Recommender Systems: Use Cases, Choosing One for Your Business
Personalized recommendation systems for growing your business.


Recommendations drive our media interactions and purchase decisions. On a global level, they push the sales numbers of every big business. On the other side of the scale is the video clip selected for autoplay while you're away from the screen to pour yourself another glass of white wine.
Of course, the wine was also suggested to you by your grocery delivery services’ product recommender because you had fish in your basket. And behind all these subtle recommendations are personalized recommender systems.
What is a ML recommender system, and how does it work?
ML recommender systems are machine learning-based recommendation models trained to recognize and systematize the content provided by the users and recommend similar pieces of content – the content based filtering. This is how we get online recommendations for finding friends, books, games, or even jobs or romantic interests.
The recommendation technology is based on the criteria we've already fed into the system without really knowing it.
Recommenders are the digital heart and soul behind driving sales and interactions. But what does the path from knowing things and recommending things look like?
Recommendation engine mechanics and types
Recommendations depend on user input – both the info about the user and what the user has interacted with, as well as additional context like geolocation, device model, time, etc.
The recommendation types can be loosely subdivided into:
- Home-page recommendations – popular items and recommendations are based on generalized matching and ranking of the previous interactions that the user had with the platform.
- Related-item recommendations – new items are recommended after a direct interaction with some piece of content.
The information about all user’s interactions with the items is scored. Certain rating points are assigned to each piece of content, and new recommendations are served. As a result of further interactions, the content is reranked, new scores are assigned, and more new content is served to the user by the recommender system.
All recommender systems can be roughly subdivided into the following types:
- Content-based – an item, its characteristics, and interaction with an item serve as a basis for recommendations.
- Collaborative filtering – assumes that the type of content preferred by the user in the past will also be favored in the future.
- Session-based – bases the recommendations on the user's interaction within a session.
- Classification-based – uses features of both the user and the product to provide recommendations.
- Reinforcement learning-based – a continuously learning, robust approach that accounts for balance in exploration and exploitation. The algorithm suggests the users the content they might find most useful, along with random content that might spark interest.
- Popularity-based – provides recommendations based on the trend and popularity principles of “trending” items based on the users' interactions within the environment.
- Risk-aware – relevant recommendations are provided to the user without considering the user's present circumstances, "risking" to deliver the recommendations regardless of the consequences – for example, late-night or persistent notifications.
- Multi-criteria – recommendations are based on several criteria and interaction types versus just one, and lean toward recommending pieces of content yet unexplored by the user.
- Hybrid systems – a hybrid approach where several recommendation systems combined together are used. We will touch upon this type later.
ML recommender systems use cases and applications
Big business companies use recommender system algorithms to provide a more customized and engaging user experience. As a result, recommenders boost retention and sales, helping companies reach their business goals.
YouTube uses a sophisticated two-stage recommender system. Their candidate generation network provides broad personalization via collaborative filtering. A small subset (hundreds) of videos from a large corpus is retrieved.
Events from the user's YouTube activity history act as input as they are considered to be highly relevant to the user. The similarity between users is noted and expressed as IDs of video watches, search query tokens, demographics, etc.
Netflix tracks what is being watched and how users interact with the platform. Ongoing A/B tests and measuring long-term satisfaction metrics via users' responses to changes in the recommendations are run.
The recommendations served by the video streaming service strive to go beyond just idea validation based on historical data or rating prediction – instead, personalized ranking, page generation, search, image selection, messaging, etc., is taken into consideration.
Facebook cannot use the traditional ML approach because of the sheer mass of data that is being processed – so sampling is not an option. A state-of-the-art deep learning open source recommendation model (DLRM) is used in combination with Facebook's open-source PyTorch and Caffe2 frameworks.
Collaborative filtering and predictive analytics-based approaches help provide recommendations based on the likes and interactions from people who have similar tastes. As a result, users discover the most relevant items through granular pieces of content that are recommended.
Instagram powers its Instagram Explore recommendations section with the help of ongoing research done by the Facebook AI team. It has created a domain-specific language optimized for retrieving candidates in recommender systems called IGQL.
Using Facebooks' nearest neighbor retrieval engine, FAISS, Instagram can serve its users a customized recommended content feed that doesn't base the recommendation on filtering all the mass of content available on the platform. Instead, the recommendations are based and served according to the session's recommendations and similar accounts' interactions.
TikTok has the main content feed called "For You", and it is fully customized for each individual user. Liked and shared videos, followed accounts, posted comments, created/uploaded content – all this determines the user's "indicator of interest" – time watched.
The machine learning recommendation system also factors in video information like the captions, sounds, and hashtags associated with the "liked" content, as well as device type, account settings, language preferences, country, geolocation, etc.
TikTok’s recommender system is optimized for performance, so the results are less precise than on other described platforms. Content from accounts with more followers is boosted on the platform.
As we can see below, these companies use recommendation engines for different purposes, promoting different kinds of content. Still, they end up leading to the same outcome – better, longer, and deeper engagement and more sales and revenue as a result.
| Product | Business type | Where recommender algorithms are used | Business outcome |
YouTube | Video content (short and long-form; user-created content) | First page, recommended next content, autoplay of recommended items | Continuous engagement with sponsored content (+ subscriptions) |
Netflix | Video content (long-form; commercially produced content) | Recommended, autoplay, related items, coming soon items | Continuous engagement with platform (+subscriptions) |
Multimedia content (various; user-created + Facebook Video section) | FAISS – friends, groups, videos | Continuous engagement with platform (ads) | |
Multimedia content (photos, videos – static and short-form; user-created) | FAISS + IGQL – follow recommendations, content on the Instagram Explore page | Continuous engagement with platform (ads) | |
TikTok | Short-form multimedia content | "For You" feed powered by a custom recommender algorithm | Continuous engagement with platform (ads) |
So how do the recommendation stems work? First, let's see what gears are spinning under the hoods of these recommendation models.

Popular recommender systems overview
Recommender engines come in all shapes and implementations, from modules to full-blown engines and cloud/SaaS solutions.
How to select the best recommender system for the business goals at hand? This overview of the most popular ones and their features should give you an idea.
| Name | Description |
A Python implementation framework that combines implicit and explicit feedback recommendation algorithms. Its diverse set of algorithm components allows creating customized recommender systems. Case Recommender uses many approaches to item recommendation, rating prediction, metrics validation, and evaluation. | |
Python-based recommender engine, which uses user-based filtering, item-based filtering, etc., and also integrates classic information filtering recommendation algorithms found in scientific Python packages like Matplotlib, Numpy, Scipy, etc. Crab aims to provide a rich component selection for constructing customized recommender systems using versatile and multi-context algorithms. | |
A successor to the Java-based LensKit toolkit, LensKit for Python is an open-source toolkit for building and researching recommender systems. It supports training, running, and evaluation of recommender algorithms. LensKit allows making robust and reproducible experiments with the help of PyData and Scientific Python ecosystem (using Scikit-learn, TensorFlow, PyTorch). | |
A Python-based fast and high-quality implementation of several popular recommendation algorithms; provides multithreaded model estimation, implicit and explicit feedback. LightFM includes efficient implementation of BPR and WARP ranking losses. It is extremely scalable and is suited for working with very large datasets on multi-core machines using Cython. | |
An open-source recommendation system written in a highly optimized Pythonic way and based on a general User-Product-Tag concept.Rexy has a flexible structure, and it's adaptable with a variant data schema. Aerospike serves as a fast, scalable, and reliable NoSQL database engine. | |
A PyTorch-based recommender system capable of building both deep and shallow recommender models. Spotlight is useful for the rapid exploration and prototyping of new recommender models.It provides building blocks for loss functions’ representations and has utilities for fetching or generating recommendation datasets and creating synthetic datasets. It also offers a number of popular datasets right out of the box: Movielens 100K, 1M, 10M, 20M. | |
A SciPy-based toolkit for analyzing and building recommender systems that deals with explicit rating data and has several built-in algorithms and datasets that help you learn by example.Surprise offers a selection of ready-to-use prediction algorithms: baseline algorithms, neighborhood methods, matrix factorization-based (SVD, PMF, SVD++, NMF, etc.). Its convenient dataset handling makes it easy to implement new algorithm ideas. | |
A Python-based recommendation system convenient for quick development and customization of recommendation algorithms with the help of TensorFlow.It learns by comparing the scores it generates based on user_features, item_features, and interactions to actual interactions between the users and items (likes, subscriptions, follows, etc.). |
While we've covered the most popular recommender systems, this is by no means an exhaustive list. If you would like to dig deeper into what's available for building your own recommender engine, you can find an extensive and detailed list of recommender systems in this repository.
A common ground for the recommender systems we've reviewed is that they take one algorithm and use it as a single primary basis for recommending.
So to find out if a given algorithm works for the business tasks at hand, numerous A/B tests are necessary. However, there is also a different approach, the one we've developed ourselves.
Hybrid real-time recommender system
At DataRoot Labs, we decided to combine the existing approaches and turn them into a flexible real-time hybrid recommender system.
By hybrid we mean a combination of a set of recommendation algorithms and an orchestration algorithm that selects an optimal subset of recommendation algorithms and optimizes the metrics.
If we consider a regular recommender system, it will take some type of user input and interactions to provide the recommendations.

Scheme 1: How regular recommender system works
But usually you will want to iterate over recommendation algorithms and have a proper set of evaluation metrics to understand which one is better. That’s where A/B testing comes in.
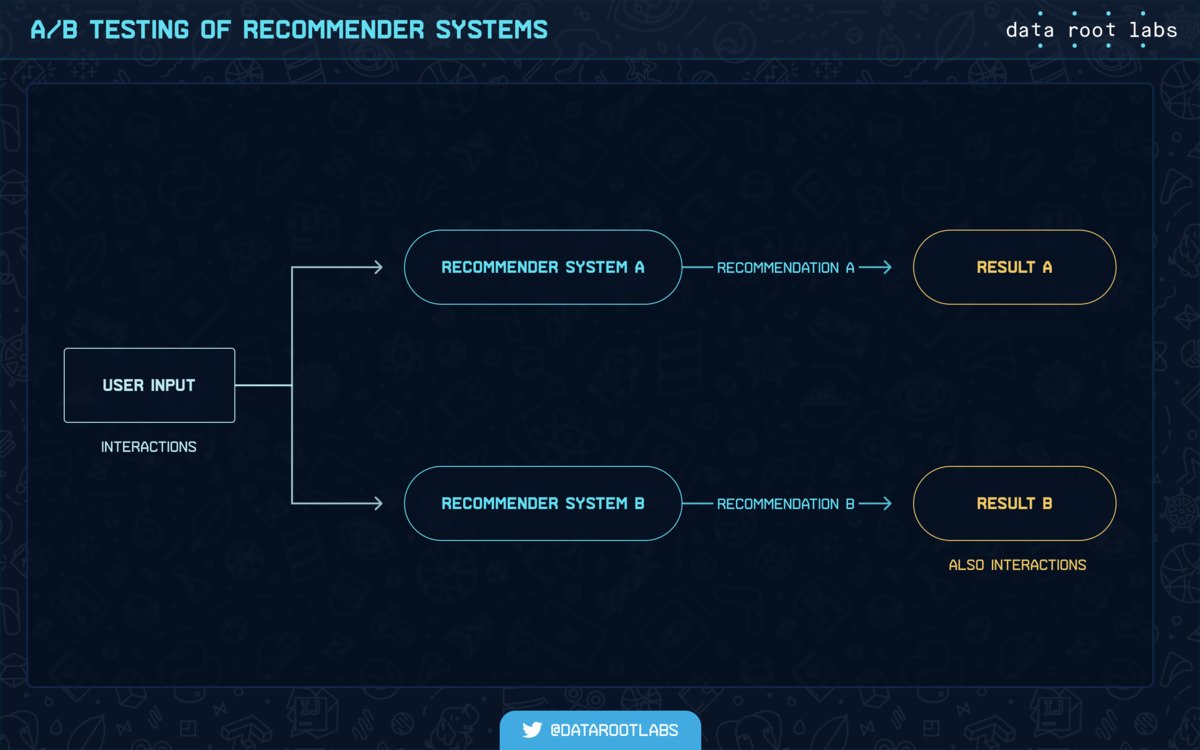
Scheme 2: A/B testing recommendations
In contrast to single-module recommendation systems described in the previous chapter, we implemented a two-level recommender system with a replaceable core that allows continuous tweaking and testing. It features two main types of algorithms and a dashboard with main metrics (such as ROI, DAU, retention, etc.):
- Recommendation algorithm
- Orchestration algorithm
The recommendation algorithm – the first algorithm in our setup – is capable of providing recommendations to the end user.
Any existing recommender piece of technology can be used here, as long as it can provide recommendations, starting with naive random, top popular, or any other simply engineered recommenders. Moreover, it can use basic implementations imported from the Surprise library and end with API of different cloud services (AWS Personalize) or completely customized architectures (as in Deezer or TikTok).
The orchestration algorithm combines different recommendation algorithms and their parameters. The input parameters (content data and user activity data) allow finding the best way to provide recommendations using a single or a combination of algorithms.
Any type of policy able to decide how different algorithms can be used here – ranging from random policy to autonomous RL system, which is able to take a new algorithm on the fly and add it to the pool of the old ones. Next, it will decide if this new algorithm is better than the previous one or two.
This way, we can continuously test different recommendation algorithms or a patch or update to previous recommendation algorithms and optimize non-differentiable business metrics (which users can track in the dashboard), which is just a reward function for the autonomous RL orchestration algorithm.
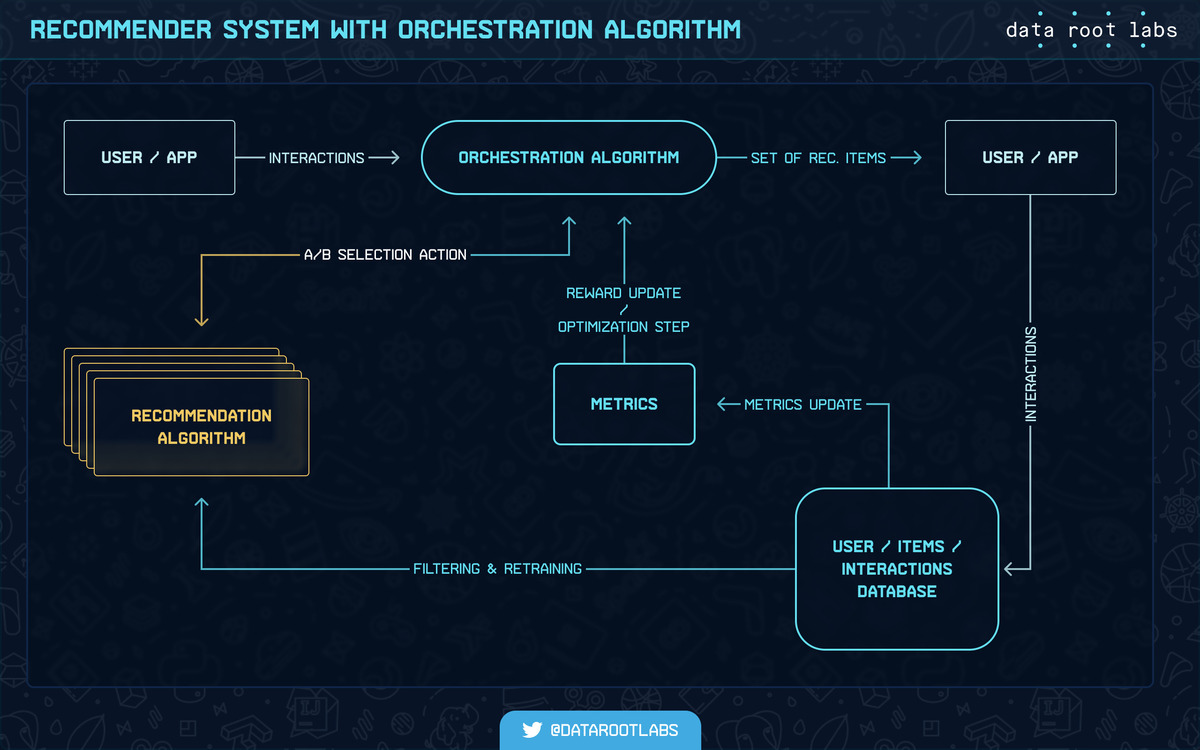
Scheme 3: Recommender combined with orchestration
This hybrid approach allows us to optimize business metrics in such a way that other recommender systems and other algorithms are not doing. We can take any algorithm or recommender engine described in this article and integrate it as a module.
How to implement a recommender engine in your project?
- Define your niche – decide what you need to recommend and to what audience.
- Explore the existing recommender system use cases within your niche.
- Clarify your data structure.
- Proceed with the technical implementation and either:
- Find a suitable end-to-end SaaS recommender engine and integrate it.
- Select a framework and implement the solution by yourself.
- Outsource the implementation to a different software company – for example, DataRoot Labs can create the solution for you.
Summary
Different recommender systems serve different purposes, but the underlying value is the same – to help the businesses that utilize them. When choosing the right recommender system for the business tasks at hand, we'd like to be flexible and test ideas and hypotheses on the go. However, this is usually a time-consuming manual process.
At DataRoot Labs, we came up with a flexible real-time hybrid recommender system that allows us to use both its own logic and other recommender engines under its hood as modules – and by any, we mean any. This should give any business a clear edge and advantage in selecting and testing what works best in a given situation.
Have an idea? Let's discuss!

Talk to Yuliya. She will make sure that all is covered. Don't waste time on googling - get all answers from relevant expert in under one hour.



Author
Co-Authors
