Advanced RAG Techniques
Practical tips for stronger Retrieval-Augmented Generation


What is RAG in Simple Words?
Before we dive into the problems and solutions, let's make sure we're on the same page about what RAG actually is.
RAG stands for Retrieval-Augmented Generation. It’s a way to make AI smarter by allowing it to pull in extra information before giving you an answer.
Here's how it works: instead of just relying on what it learned during training, the AI first searches through a database or collection of documents to find relevant info about your question. Then it uses that fresh information to give you a better, more accurate answer.
It's like the difference between answering from memory versus being able to quickly check your notes. This way, AI can give you current information and cite specific sources, rather than just guessing based on old training data.
How Traditional RAG Actually Works
Traditional Retrieval-Augmented Generation (RAG) operates through a straightforward pipeline designed to enhance Large Language Models with external knowledge. Let's break down each component.
All examples in this article use the LangChain framework combined with FAISS as the vector store and OpenAI’s API for embeddings and generation.
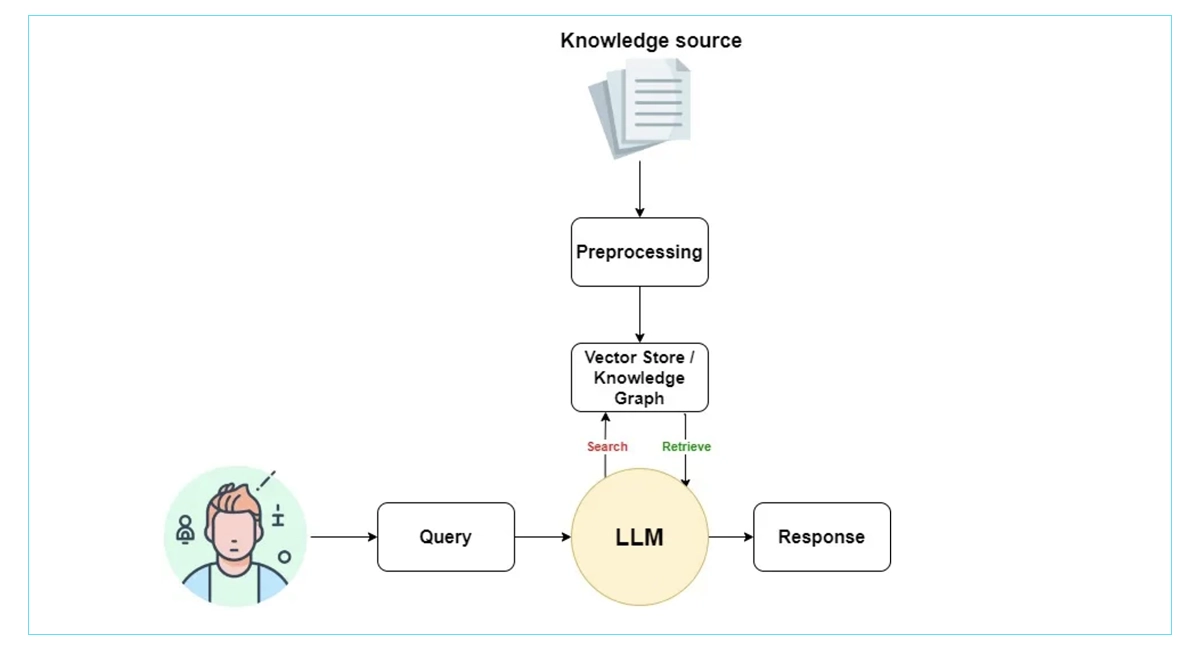
Baseline RAG
DOCUMENT PROCESSING & CHUNKING
The foundation of any RAG system begins with preparing your knowledge base. Documents are split into smaller, manageable chunks that can be effectively processed and retrieved.
# Install dependencies and setup env:
# !pip install -qU langchain faiss-cpu openai tiktoken langchain-openai langchain_community
import os
import getpass
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, OpenAI
from langchain.vectorstores import FAISS
from openai import OpenAI
raw_docs = [
"""Retrieval-Augmented Generation (RAG) is a technique where a language model is supplied with additional context retrieved from an external knowledge base. It improves factual accuracy and reduces hallucinations.""",
"""Vector databases such as Chroma, FAISS, or Milvus store embeddings and perform approximate-nearest-neighbor (ANN) search to fetch semantically similar chunks in milliseconds, even at billion-scale.""",
"""Chunking strategy matters: overlapping windows preserve long-range coherence, while hierarchical splitting (paragraph → sentence → word) minimizes information loss."""
]
documents = [Document(page_content=text) for text in raw_docs]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=200,
separators=["\n\n", "\n", " ", ""],
)
chunks = text_splitter.split_documents(documents)
print(f"Split documents into {len(chunks)} chunks")
Key Functions:
- Maintains semantic coherence within chunks
- Preserves context through overlapping segments
- Optimizes chunk size for embedding models
- Handles various document formats (PDF, HTML, markdown)
EMBEDDING GENERATION
Each text chunk is converted into high-dimensional vectors (embeddings) that capture semantic meaning. These embeddings enable similarity-based retrieval.
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(
documents=chunks,
embedding=embeddings
)
vectorstore.save_local("./faiss_index")
print("FAISS vector store created successfully")
Key Functions:
- Transforms text into mathematical representations
- Captures semantic relationships between concepts
- Enables fast similarity search across large datasets
- Supports multilingual understanding
VECTOR STORAGE & INDEXING
Embeddings are stored in specialized vector databases optimized for similarity search. These systems use algorithms like FAISS, HNSW, or IVF for efficient retrieval.
Key Functions:
- Fast approximate nearest neighbor search
- Scalable storage for millions of vectors
- Support for metadata filtering
- Real-time index updates
QUERY PROCESSING & RETRIEVAL
When a user asks a question, it's converted to an embedding and compared against stored vectors to find the most semantically similar chunks.
def retrieve_documents(query: str, k: int = 4):
"""
Embed the user's query and return the k most similar chunks.
"""
similar_docs = vectorstore.similarity_search(query=query, k=k)
return similar_docs
# quick smoke-test
retrieved_docs = retrieve_documents("Why use a vector database?")
for i, d in enumerate(retrieved_docs):
print(f"{i+1}. {d.page_content[:90].strip()}...\n")
Key Functions:
- Semantic similarity matching
- Relevance scoring and ranking
- Metadata-based filtering
- Multi-modal query support
CONTEXT ASSEMBLY & GENERATION
Retrieved chunks are assembled into a context prompt that's fed to the LLM along with the original query for response generation.
llm = OpenAI(temperature=0)
def generate_response(query: str, retrieved_docs):
context = "\n\n".join(d.page_content for d in retrieved_docs)
# Create prompt template
prompt_template = PromptTemplate(
input_variables=["context", "question"],
template="""You are an assistant who answers questions ONLY with information found in the provided context.
If the answer isn't there, reply: 'I don't know'.
Context:
{context}
Question: {question}
Answer:"""
)
chain = prompt_template | llm
response = chain.invoke({"context": context, "question": query})
return response.strip()
question = "What benefit does overlapping chunk windows provide?"
docs = retrieve_documents(question, k=3)
answer = generate_response(question, docs)
print("Q:", question)
print("A:", answer)
Key Functions:
- Context compilation and formatting
- Prompt engineering for optimal results
- Response generation with source attribution
- Quality control and filtering
This pipeline works well for straightforward questions, but it starts to break down when things get complicated.
The Reality Check: Where Basic RAG Falls Short
You've built your first RAG system following this standard approach. It works... sort of. Sometimes it gives brilliant answers, other times it completely misses the mark. Sound familiar? You're not alone.
Let's see what's actually happening behind the scenes when your RAG system disappoints you.
Connection Blindness
Your system treats every chunk as an island. When you ask "How do climate policies in different countries affect global supply chains?", it might find great chunks about climate policies and separate chunks about supply chains, but it completely misses the connections between them.
Context Fragmentation
Complex queries that need a holistic view across multiple documents often fail. Ask for "the top 5 themes from all company reports" and you'll get isolated text fragments instead of meaningful insights that synthesize information from across your knowledge base.
Semantic Gaps
Vector similarity isn't perfect. Sometimes "CEO" and "Chief Executive Officer" don't get recognized as the same thing in context. Your system might miss crucial information because it's looking for semantic similarity but missing conceptual relationships.
Static Retrieval
Whether you ask "What's the capital of France?" or "Analyze the complex interplay between monetary policy, inflation expectations, and consumer behavior across different market cycles," you get the same number of chunks. Simple questions end up mixed with too much irrelevant context, while complex ones don't get enough information.
Ranking Limitations
Just because two pieces of text are semantically similar doesn't mean they're both useful for answering your specific question. Traditional similarity scoring often misses what's actually relevant.
Beyond Baseline: Advanced RAG Approaches
The good news? Smart people have been working on these exact problems. The truth is, traditional RAG is just the starting point. If you want to build something that actually works reliably in production, you need to level up your approach.
Here are the advanced RAG techniques that can fix these limitations:
- Graph RAG structures knowledge as interconnected entities and relationships
- Hybrid RAG combines multiple retrieval methods for comprehensive coverage
- RAG Fusion uses multi-query strategies to capture different query aspects
- Unstructured RAG handles mixed content types including text, tables, and images
- Contextual RAG intelligently compresses information to focus on relevance
Let's explore how each approach solves specific problems and when to use them.
Graph RAG - When Connections Matter
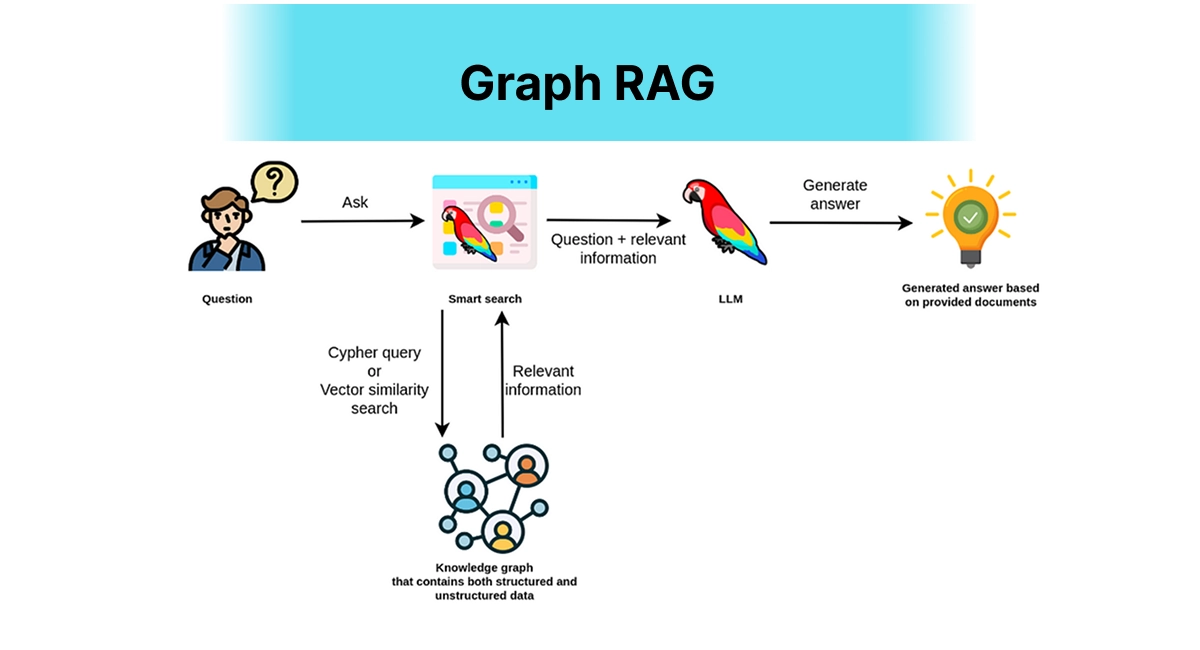
Graph RAG
The Problem It Solves
Your knowledge base isn't just a pile of documents - it's a web of connected information. Traditional RAG misses these connections entirely.
How It Works
Instead of treating your data as independent chunks, Graph RAG maps out entities and their relationships. Think of it like LinkedIn for your documents - everything is connected to everything else in meaningful ways.
When to Use It
- Complex research questions that span multiple documents
- When you need to understand relationships between entities
- For knowledge bases where context and connections are crucial
Real-World Example: imagine asking "How do climate policies in different countries affect global supply chains?". A basic RAG might pull random facts about policies and supply chains. Graph RAG understands the connections and can trace the relationships between specific policies and their downstream effects.
Implementation Spotlight: GraphRAG
import numpy as np
from typing import List, Dict, Tuple
import networkx as nx
from sklearn.metrics.pairwise import cosine_similarity
from langchain_openai import OpenAI
from langchain.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
class SimpleGraphRAG:
def __init__(self, openai_api_key: str):
self.embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
self.llm = OpenAI(openai_api_key=openai_api_key, temperature=0)
self.knowledge_graph = nx.Graph()
self.vector_store = None
self.documents = []
def process_documents(self, texts: List[str], chunk_size: int = 500):
"""Split documents and create initial embeddings"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=50
)
all_chunks = []
for text in texts:
chunks = splitter.split_text(text)
all_chunks.extend(chunks)
self.documents = all_chunks
self.vector_store = FAISS.from_texts(all_chunks, self.embeddings)
def extract_entities_and_relationships(self, text: str) -> Dict:
"""Extract entities and relationships using LLM"""
entity_prompt = PromptTemplate(
input_variables=["text"],
template="""
Extract the main entities and their relationships from the following text.
Format your response as:
ENTITIES: entity1, entity2, entity3, ...
RELATIONSHIPS: entity1 -> entity2 (relationship_type), entity2 -> entity3 (relationship_type), ...
Text: {text}
"""
)
chain = entity_prompt | self.llm
response = chain.invoke(input=text)
return self._parse_extraction_response(response)
def _parse_extraction_response(self, response: str) -> Dict:
"""Parse the LLM response to extract entities and relationships"""
lines = response.strip().split('\n')
entities = []
relationships = []
for line in lines:
if line.startswith('ENTITIES:'):
entities = [e.strip() for e in line.replace('ENTITIES:', '').split(',')]
elif line.startswith('RELATIONSHIPS:'):
rel_text = line.replace('RELATIONSHIPS:', '').strip()
if rel_text:
relationships = self._parse_relationships(rel_text)
return {"entities": entities, "relationships": relationships}
def _parse_relationships(self, rel_text: str) -> List[Tuple]:
"""Parse relationship text into tuples"""
relationships = []
if not rel_text:
return relationships
parts = rel_text.split(',')
for part in parts:
if '->' in part:
try:
rel_parts = part.strip().split('->')
if len(rel_parts) == 2:
entity1 = rel_parts[0].strip()
rest = rel_parts[1].strip()
if '(' in rest and ')' in rest:
entity2 = rest.split('(')[0].strip()
rel_type = rest.split('(')[1].split(')')[0].strip()
relationships.append((entity1, entity2, rel_type))
except:
continue
return relationships
def build_knowledge_graph(self):
"""Build knowledge graph from processed documents"""
for i, doc in enumerate(self.documents):
extraction = self.extract_entities_and_relationships(doc)
for entity in extraction["entities"]:
if entity and entity.strip():
self.knowledge_graph.add_node(
entity,
document_ids=[i],
text_chunk=doc[:200]
)
for entity1, entity2, rel_type in extraction["relationships"]:
if entity1 and entity2 and entity1.strip() and entity2.strip():
self.knowledge_graph.add_edge(
entity1,
entity2,
relationship=rel_type,
document_id=i
)
def graph_traversal_search(self, query_entities: List[str], max_hops: int = 2) -> List[str]:
"""Find relevant nodes through graph traversal"""
relevant_nodes = set()
for entity in query_entities:
if entity in self.knowledge_graph:
relevant_nodes.add(entity)
for hop in range(max_hops):
current_nodes = list(relevant_nodes)
for node in current_nodes:
if node in self.knowledge_graph:
neighbors = list(self.knowledge_graph.neighbors(node))
relevant_nodes.update(neighbors)
return list(relevant_nodes)
def retrieve_context(self, query: str, k: int = 5) -> str:
"""Retrieve relevant context using both vector similarity and graph traversal"""
vector_results = self.vector_store.similarity_search(query, k=k)
vector_texts = [doc.page_content for doc in vector_results]
query_extraction = self.extract_entities_and_relationships(query)
query_entities = query_extraction["entities"]
graph_nodes = self.graph_traversal_search(query_entities)
graph_texts = []
for node in graph_nodes[:k]:
if node in self.knowledge_graph:
node_data = self.knowledge_graph.nodes[node]
if 'text_chunk' in node_data:
graph_texts.append(node_data['text_chunk'])
all_contexts = vector_texts + graph_texts
unique_contexts = list(dict.fromkeys(all_contexts))
return "\n\n".join(unique_contexts[:k])
def query(self, question: str) -> str:
"""Answer a question using Graph RAG"""
context = self.retrieve_context(question)
answer_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the following context, answer the question as accurately as possible.
Context:
{context}
Question: {question}
Answer:
"""
)
chain = answer_prompt | self.llm
answer = chain.invoke({"context": context, "question": question})
return answer.strip()
# Usage example:
graph_rag = SimpleGraphRAG(openai_api_key="your-openai-api-key")
documents = [
"""
Alice is a software engineer at TechCorp. She works on machine learning projects
and reports to Bob, who is the head of the AI department. TechCorp is located in
San Francisco and focuses on developing AI solutions for healthcare.
""",
"""
Bob leads the AI department at TechCorp. He has 10 years of experience in artificial
intelligence and previously worked at Google. The AI department consists of 15 engineers
including Alice and Charlie. They are currently working on a medical diagnosis system.
""",
"""
Charlie is a senior engineer in TechCorp's AI department. He specializes in natural
language processing and has published several papers on transformer models. Charlie
and Alice often collaborate on NLP-related features for the medical diagnosis system.
"""
]
print("Processing documents...")
graph_rag.process_documents(documents)
print("Building knowledge graph...")
graph_rag.build_knowledge_graph()
print(f"Knowledge graph built with {graph_rag.knowledge_graph.number_of_nodes()} nodes and {graph_rag.knowledge_graph.number_of_edges()} edges")
questions = [
"Who does Alice report to?",
"What is TechCorp working on?",
"Who are the people working on NLP at TechCorp?"
]
for question in questions:
print(f"\nQuestion: {question}")
answer = graph_rag.query(question)
print(f"Answer: {answer}")
Hybrid RAG - Getting the Best of Both Worlds
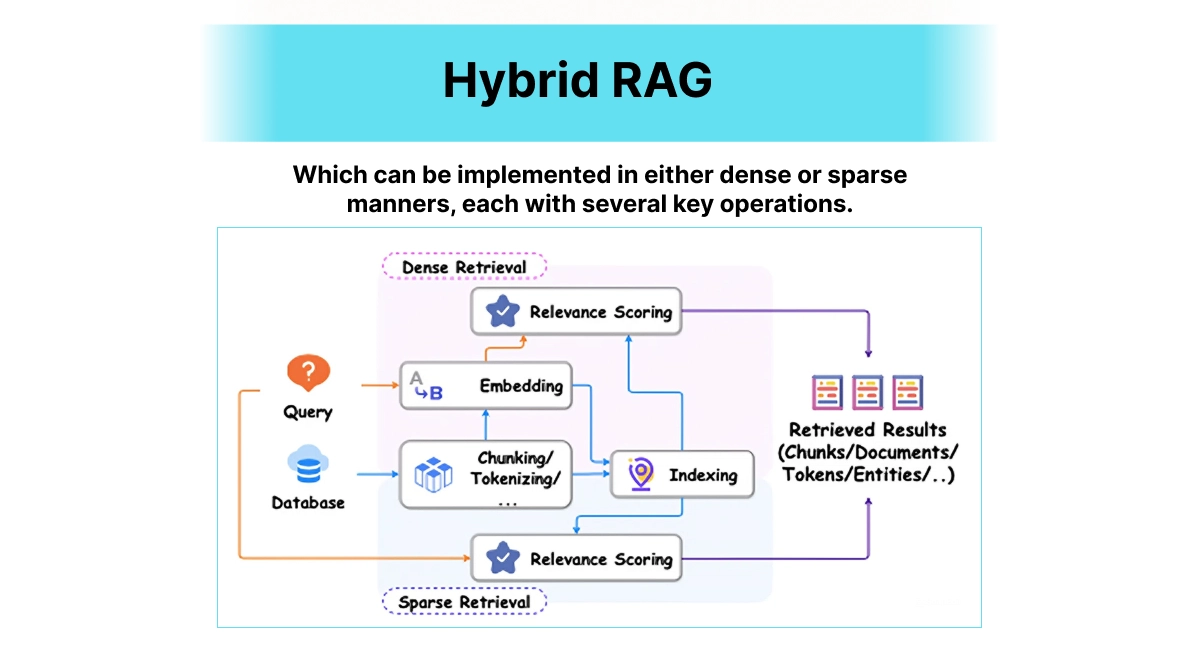
Hybrid RAG
The Problem It Solves
Sometimes you need semantic understanding, sometimes you need exact matches. Why choose?
How It Works
Combines vector search (great for semantic similarity) with traditional keyword search like BM25 (perfect for exact matches). It's like having both a smart research assistant and a precise librarian working together.
When to Use It
- When users might search with specific technical terms or product names
- For content with important exact phrases or codes
- When you want to reduce the chance of missing relevant documents
Tip: Most production RAG systems should probably be hybrid by default. The performance improvement is usually worth the extra complexity.
Simple Implementation of Hybrid RAG
import re
import math
import numpy as np
from collections import Counter
from typing import List, Dict, Tuple
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizer
from langchain_openai import OpenAI
from langchain.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
class BM25Retriever:
"""Simple BM25 implementation for keyword-based retrieval"""
def __init__(self, k1: float = 1.5, b: float = 0.75):
self.k1 = k1
self.b = b
self.corpus = []
self.doc_freqs = []
self.idf = {}
self.doc_len = []
self.avgdl = 0
def fit(self, corpus: List[str]):
"""Fit BM25 on a corpus of documents"""
self.corpus = corpus
self.doc_len = [len(doc.split()) for doc in corpus]
self.avgdl = sum(self.doc_len) / len(self.doc_len)
df = Counter()
for doc in corpus:
words = set(self._tokenize(doc))
df.update(words)
num_docs = len(corpus)
for word, freq in df.items():
self.idf[word] = math.log((num_docs - freq + 0.5) / (freq + 0.5))
def _tokenize(self, text: str) -> List[str]:
"""Simple tokenization"""
return re.findall(r'\b\w+\b', text.lower())
def get_scores(self, query: str) -> List[float]:
"""Get BM25 scores for all documents given a query"""
query_words = self._tokenize(query)
scores = []
for i, doc in enumerate(self.corpus):
doc_words = self._tokenize(doc)
doc_word_counts = Counter(doc_words)
score = 0
for word in query_words:
if word in doc_word_counts:
freq = doc_word_counts[word]
idf = self.idf.get(word, 0)
numerator = freq * (self.k1 + 1)
denominator = freq + self.k1 * (1 - self.b + self.b * (self.doc_len[i] / self.avgdl))
score += idf * (numerator / denominator)
scores.append(score)
return scores
def retrieve(self, query: str, k: int = 5) -> List[Tuple[int, float]]:
"""Retrieve top k documents with their scores"""
scores = self.get_scores(query)
scored_docs = [(i, score) for i, score in enumerate(scores)]
scored_docs.sort(key=lambda x: x[1], reverse=True)
return scored_docs[:k]
class HybridRAG:
"""Hybrid RAG combining vector search and BM25 keyword search"""
def __init__(self, openai_api_key: str, vector_weight: float = 0.7):
self.embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
self.llm = OpenAI(openai_api_key=openai_api_key, temperature=0)
self.vector_store = None
self.bm25_retriever = BM25Retriever()
self.documents = []
self.vector_weight = vector_weight
self.bm25_weight = 1.0 - vector_weight
def process_documents(self, texts: List[str], chunk_size: int = 500):
"""Process documents for both vector and keyword search"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=50
)
all_chunks = []
for text in texts:
chunks = splitter.split_text(text)
all_chunks.extend(chunks)
self.documents = all_chunks
print("Creating vector embeddings...")
self.vector_store = FAISS.from_texts(all_chunks, self.embeddings)
print("Training BM25 retriever...")
self.bm25_retriever.fit(all_chunks)
def normalize_scores(self, scores: List[float]) -> List[float]:
"""Normalize scores to 0-1 range using min-max scaling"""
if not scores or max(scores) == min(scores):
return [0.0] * len(scores)
min_score = min(scores)
max_score = max(scores)
return [(score - min_score) / (max_score - min_score) for score in scores]
def hybrid_retrieve(self, query: str, k: int = 5) -> List[Tuple[str, float]]:
"""Retrieve documents using hybrid approach"""
vector_results = self.vector_store.similarity_search_with_score(query, k=len(self.documents))
vector_scores = {}
for doc, distance in vector_results:
doc_index = self.documents.index(doc.page_content)
similarity = 1 / (1 + distance)
vector_scores[doc_index] = similarity
bm25_results = self.bm25_retriever.retrieve(query, k=len(self.documents))
bm25_scores = {doc_idx: score for doc_idx, score in bm25_results}
vector_score_list = [vector_scores.get(i, 0) for i in range(len(self.documents))]
bm25_score_list = [bm25_scores.get(i, 0) for i in range(len(self.documents))]
normalized_vector = self.normalize_scores(vector_score_list)
normalized_bm25 = self.normalize_scores(bm25_score_list)
hybrid_scores = []
for i in range(len(self.documents)):
combined_score = (
self.vector_weight * normalized_vector[i] +
self.bm25_weight * normalized_bm25[i]
)
hybrid_scores.append((i, combined_score))
hybrid_scores.sort(key=lambda x: x[1], reverse=True)
results = []
for doc_idx, score in hybrid_scores[:k]:
results.append((self.documents[doc_idx], score))
return results
def explain_retrieval(self, query: str, k: int = 5) -> Dict:
"""Explain how documents were retrieved for debugging/understanding"""
vector_results = self.vector_store.similarity_search_with_score(query, k=k)
bm25_results = self.bm25_retriever.retrieve(query, k=k)
hybrid_results = self.hybrid_retrieve(query, k=k)
explanation = {
"query": query,
"vector_results": [
{"text": doc.page_content[:100] + "...", "distance": float(distance)}
for doc, distance in vector_results
],
"bm25_results": [
{"text": self.documents[idx][:100] + "...", "score": float(score)}
for idx, score in bm25_results
],
"hybrid_results": [
{"text": text[:100] + "...", "score": float(score)}
for text, score in hybrid_results
],
"weights": {
"vector_weight": self.vector_weight,
"bm25_weight": self.bm25_weight
}
}
return explanation
def query(self, question: str, k: int = 5) -> str:
"""Answer a question using hybrid retrieval"""
hybrid_results = self.hybrid_retrieve(question, k=k)
contexts = [text for text, score in hybrid_results]
combined_context = "\n\n".join(contexts)
answer_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the following context, answer the question as accurately as possible.
Context:
{context}
Question: {question}
Answer:
"""
)
chain = answer_prompt | self.llm
answer = chain.invoke({"context": combined_context, "question": question})
return answer.strip()
# Usage example:
hybrid_rag = HybridRAG(openai_api_key="your-openai-api-key", vector_weight=0.7)
documents = [
"""
TechCorp's AI-ML-2024 model achieves 94.5% accuracy on medical diagnosis tasks.
The model uses transformer architecture and was trained on 50,000 medical records.
Error code: ERR_DIAG_001 indicates insufficient training data.
""",
"""
Our latest product, DataViz Pro v3.2.1, includes advanced visualization features.
Product SKU: DVP-3.2.1-ENT. License key format: DVP-XXXX-XXXX-XXXX-XXXX.
The software integrates machine learning algorithms for predictive analytics.
""",
"""
Machine learning models require careful tuning of hyperparameters. Deep learning
approaches have shown significant improvements in natural language processing tasks.
The neural network architecture uses attention mechanisms for better performance.
""",
"""
Customer support ticket #CS-2024-0892: User reports authentication error when
accessing DataViz Pro. Error message: "Invalid license key DVP-1234-5678-9012-3456".
Resolution: Generate new license key through admin panel.
""",
"""
Research shows that artificial intelligence applications in healthcare have
tremendous potential. AI models can assist doctors in diagnosing diseases more
accurately and efficiently. Deep neural networks excel at pattern recognition.
"""
]
print("Processing documents for hybrid search...")
hybrid_rag.process_documents(documents)
test_queries = [
# Semantic query - should benefit from vector search
"How accurate are AI models for medical diagnosis?",
# Exact match query - should benefit from BM25
"What is error code ERR_DIAG_001?",
# Product-specific query - benefits from both approaches
"Issues with DataViz Pro license key",
# Mixed semantic + exact - perfect for hybrid
"machine learning accuracy in medical applications"
]
print("\n" + "="*60)
print("HYBRID RAG RESULTS")
print("="*60)
for query in test_queries:
print(f"\nQuery: {query}")
print("-" * 40)
answer = hybrid_rag.query(query, k=3)
print(f"Answer: {answer}")
explanation = hybrid_rag.explain_retrieval(query, k=3)
print("\nRetrieval Analysis:")
print(f"Vector search top result: {explanation['vector_results'][0]['text']}")
print(f"BM25 search top result: {explanation['bm25_results'][0]['text']}")
print(f"Hybrid search top result: {explanation['hybrid_results'][0]['text']}")
print(f"Hybrid score: {explanation['hybrid_results'][0]['score']:.3f}")
print("\n" + "="*60)
print("TESTING DIFFERENT WEIGHTS")
print("="*60)
hybrid_rag_exact = HybridRAG(openai_api_key="your-openai-api-key", vector_weight=0.3)
hybrid_rag_exact.process_documents(documents)
query = "error code ERR_DIAG_001"
print(f"\nQuery: {query}")
print("\nVector-heavy (0.7 vector, 0.3 BM25):")
result1 = hybrid_rag.hybrid_retrieve(query, k=1)
print(f"Top result: {result1[0][0][:100]}...")
print(f"Score: {result1[0][1]:.3f}")
print("\nBM25-heavy (0.3 vector, 0.7 BM25):")
result2 = hybrid_rag_exact.hybrid_retrieve(query, k=1)
print(f"Top result: {result2[0][0][:100]}...")
print(f"Score: {result2[0][1]:.3f}")
RAG Fusion - Asking Better Questions
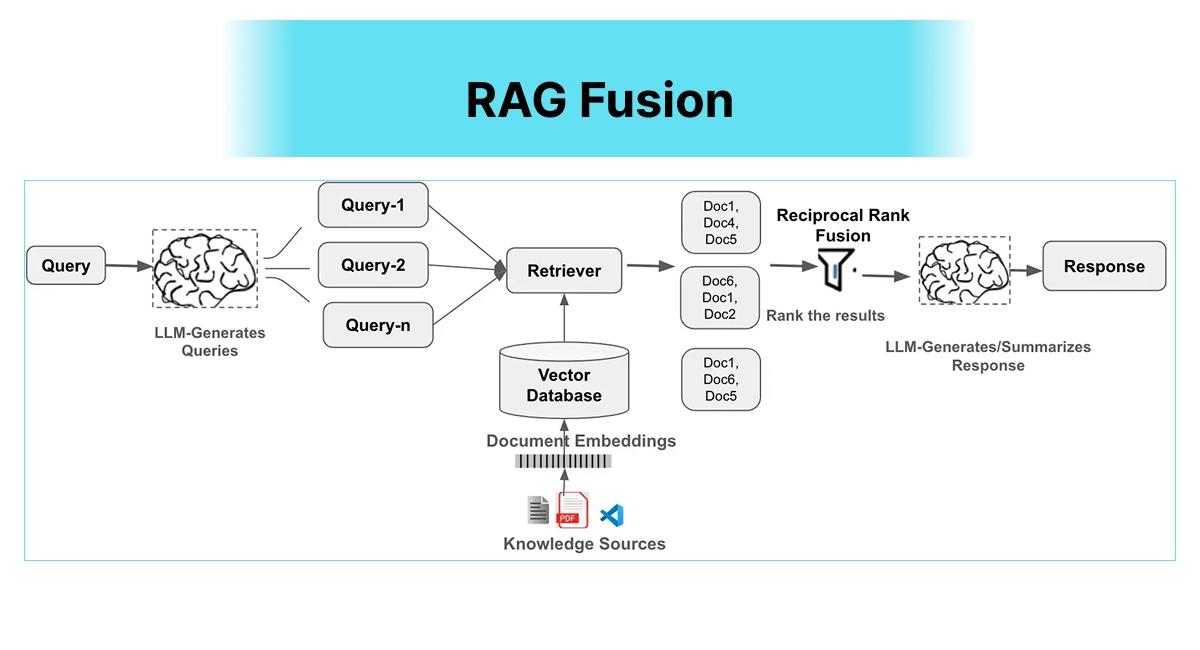
RAG Fusion
The Problem It Solves
Users ask questions in one way, but the answer might be found under completely different phrasing.
How It Works
Takes your original question and generates multiple related sub-questions, then searches for each one separately. Finally, it intelligently combines all the results using something called Reciprocal Rank Fusion.
When to Use It
- For complex questions with multiple aspects
- When you want comprehensive coverage of a topic
- For user-facing applications where query quality varies widely
Example in Action
- Original: "How do I improve my team's productivity?"
- Generated sub-queries: "team productivity metrics," "productivity improvement strategies," "team efficiency tools," "workplace productivity challenges"
Naive Implementation of RAG Fusion
import re
import math
from collections import defaultdict
from typing import List, Dict, Tuple, Set
from langchain_openai import OpenAI
from langchain.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
class RAGFusion:
"""RAG Fusion implementation with query expansion and Reciprocal Rank Fusion"""
def __init__(self, openai_api_key: str, num_queries: int = 4):
self.embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
self.llm = OpenAI(openai_api_key=openai_api_key, temperature=0.3)
self.vector_store = None
self.documents = []
self.num_queries = num_queries
def process_documents(self, texts: List[str], chunk_size: int = 500):
"""Process documents and create vector store"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=50
)
all_chunks = []
for text in texts:
chunks = splitter.split_text(text)
all_chunks.extend(chunks)
self.documents = all_chunks
print("Creating vector embeddings...")
self.vector_store = FAISS.from_texts(all_chunks, self.embeddings)
def generate_sub_queries(self, original_query: str) -> List[str]:
"""Generate multiple related queries from the original question"""
query_generation_prompt = PromptTemplate(
input_variables=["original_query", "num_queries"],
template="""You are an AI assistant that helps generate multiple search queries.
Given the original query, generate {num_queries} different but related search queries that would help find relevant information.
Original Query: {original_query}
Generate exactly {num_queries} alternative queries, one per line:
1.
2.
3.
4."""
)
try:
chain = query_generation_prompt | self.llm
response = chain.invoke({
"original_query": original_query,
"num_queries": self.num_queries
})
generated_queries = []
lines = response.strip().split('\n')
for line in lines:
line = line.strip()
if line and any(char.isalpha() for char in line):
cleaned = re.sub(r'^\d+[\.\)\-\s]*', '', line).strip()
if cleaned and len(cleaned) > 5:
generated_queries.append(cleaned)
all_queries = [original_query] + generated_queries[:self.num_queries]
unique_queries = []
seen_lower = set()
for query in all_queries:
if query.lower() not in seen_lower:
unique_queries.append(query)
seen_lower.add(query.lower())
if len(unique_queries) >= self.num_queries + 1:
break
return unique_queries
except Exception as e:
print(f"Error generating sub-queries: {e}")
return [original_query]
def search_multiple_queries(self, queries: List[str], k: int = 5) -> Dict[str, List[Tuple[str, float]]]:
"""Search for each query and return results"""
all_results = {}
for query in queries:
results = self.vector_store.similarity_search_with_score(query, k=k)
query_results = []
for doc, distance in results:
similarity_score = 1 / (1 + distance)
query_results.append((doc.page_content, similarity_score))
all_results[query] = query_results
return all_results
def reciprocal_rank_fusion(self, query_results: Dict[str, List[Tuple[str, float]]], k: int = 60) -> List[Tuple[str, float]]:
"""
Apply Reciprocal Rank Fusion to combine results from multiple queries
RRF formula: RRF(d) = Σ(1 / (k + rank(d)))
"""
doc_scores = defaultdict(float)
doc_texts = {}
for query, results in query_results.items():
for rank, (doc_text, original_score) in enumerate(results, 1):
rrf_score = 1.0 / (k + rank)
doc_key = doc_text[:100]
doc_scores[doc_key] += rrf_score
doc_texts[doc_key] = doc_text
fused_results = []
for doc_key, fusion_score in sorted(doc_scores.items(), key=lambda x: x[1], reverse=True):
fused_results.append((doc_texts[doc_key], fusion_score))
return fused_results
def explain_fusion_process(self, original_query: str, k: int = 5) -> Dict:
"""Explain the RAG Fusion process step by step"""
print(f"\nRAG FUSION PROCESS for: '{original_query}'")
print("=" * 60)
print("\nStep 1: Generating sub-queries...")
sub_queries = self.generate_sub_queries(original_query)
explanation = {
"original_query": original_query,
"generated_queries": sub_queries,
"individual_results": {},
"fusion_results": []
}
print(f"Generated {len(sub_queries)} queries:")
for i, query in enumerate(sub_queries, 1):
print(f" {i}. {query}")
print("\nStep 2: Searching for each query...")
query_results = self.search_multiple_queries(sub_queries, k=k)
for query, results in query_results.items():
print(f"\nQuery: '{query[:50]}...'")
explanation["individual_results"][query] = []
for i, (doc, score) in enumerate(results[:3], 1):
preview = doc[:80].replace('\n', ' ') + "..."
print(f" {i}. [{score:.3f}] {preview}")
explanation["individual_results"][query].append({
"rank": i,
"score": score,
"preview": preview
})
print("\nStep 3: Applying Reciprocal Rank Fusion...")
fused_results = self.reciprocal_rank_fusion(query_results, k=60)
print("Top 5 fused results:")
for i, (doc, fusion_score) in enumerate(fused_results[:5], 1):
preview = doc[:80].replace('\n', ' ') + "..."
print(f" {i}. [Fusion Score: {fusion_score:.4f}] {preview}")
explanation["fusion_results"].append({
"rank": i,
"fusion_score": fusion_score,
"preview": preview
})
return explanation
def retrieve_with_fusion(self, query: str, k: int = 5) -> List[str]:
"""Retrieve documents using RAG Fusion approach"""
queries = self.generate_sub_queries(query)
query_results = self.search_multiple_queries(queries, k=k)
fused_results = self.reciprocal_rank_fusion(query_results)
return [doc for doc, score in fused_results[:k]]
def query(self, question: str, k: int = 5, explain: bool = False) -> str:
"""Answer a question using RAG Fusion"""
if explain:
self.explain_fusion_process(question, k=k)
contexts = self.retrieve_with_fusion(question, k=k)
combined_context = "\n\n".join(contexts)
answer_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the following context retrieved through multiple search strategies,
answer the question as comprehensively and accurately as possible.
Context:
{context}
Question: {question}
Answer:
"""
)
chain = answer_prompt | self.llm
answer = chain.invoke({"context": combined_context, "question": question})
return answer.strip()
# Usage example:
rag_fusion = RAGFusion(openai_api_key="your-openai-api-key", num_queries=4)
documents = [
"""
Team productivity can be measured through various metrics including task completion rates,
quality of deliverables, and time-to-completion. Effective teams typically show consistent
improvement in these areas over time. Key performance indicators should align with business objectives.
""",
"""
Common productivity challenges in teams include poor communication, lack of clear goals,
insufficient resources, and unclear priorities. Teams often struggle with context switching
between multiple projects and meetings that interrupt deep work time.
""",
"""
Productivity improvement strategies include implementing agile methodologies, using
collaborative tools like Slack and Asana, establishing clear workflows, and regular
retrospectives. Time-blocking and focus sessions can significantly improve individual output.
""",
"""
Technology tools for team efficiency include project management platforms, communication
software, automation tools, and analytics dashboards. Popular options include Trello, Jira,
Microsoft Teams, and Zoom. The key is choosing tools that integrate well together.
""",
"""
Workplace productivity is influenced by factors such as office environment, work-life balance,
employee engagement, and leadership style. Remote work has introduced new challenges and
opportunities for productivity optimization through digital collaboration.
""",
"""
Team dynamics play a crucial role in productivity. High-performing teams exhibit trust,
psychological safety, clear roles, and effective conflict resolution. Regular team building
and open communication channels foster better collaboration and results.
""",
"""
Measuring team performance requires both quantitative metrics (velocity, cycle time, defect rates)
and qualitative assessments (team satisfaction, collaboration quality, innovation). Balanced
scorecards can provide comprehensive views of team effectiveness.
""",
"""
Productivity obstacles often include unclear requirements, technical debt, insufficient training,
and organizational silos. Addressing these systematically through process improvements and
better resource allocation can yield significant productivity gains.
"""
]
print("Processing documents for RAG Fusion...")
rag_fusion.process_documents(documents)
test_questions = [
"How do I improve my team's productivity?",
"What are the biggest obstacles to workplace efficiency?",
"How can I measure if my team is performing well?",
"What tools should we use for better collaboration?"
]
print("\n" + "="*80)
print("RAG FUSION DEMONSTRATION")
print("="*80)
for question in test_questions:
print(f"\n{'QUESTION: ' + question}")
print("="*60)
answer = rag_fusion.query(question, k=4, explain=True)
print(f"\nFINAL ANSWER:")
print("-" * 40)
print(answer)
print("\n" + "="*60)
print("\n" + "="*80)
print("COMPARISON: Regular Search vs RAG Fusion")
print("="*80)
question = "How do I improve my team's productivity?"
print(f"\nRegular RAG (single query):")
regular_results = rag_fusion.vector_store.similarity_search(question, k=3)
for i, doc in enumerate(regular_results, 1):
preview = doc.page_content[:100].replace('\n', ' ') + "..."
print(f" {i}. {preview}")
print(f"\nRAG Fusion (multiple queries + fusion):")
fusion_results = rag_fusion.retrieve_with_fusion(question, k=3)
for i, doc in enumerate(fusion_results, 1):
preview = doc[:100].replace('\n', ' ') + "..."
print(f" {i}. {preview}")
Unstructured RAG - Beyond Plain Text
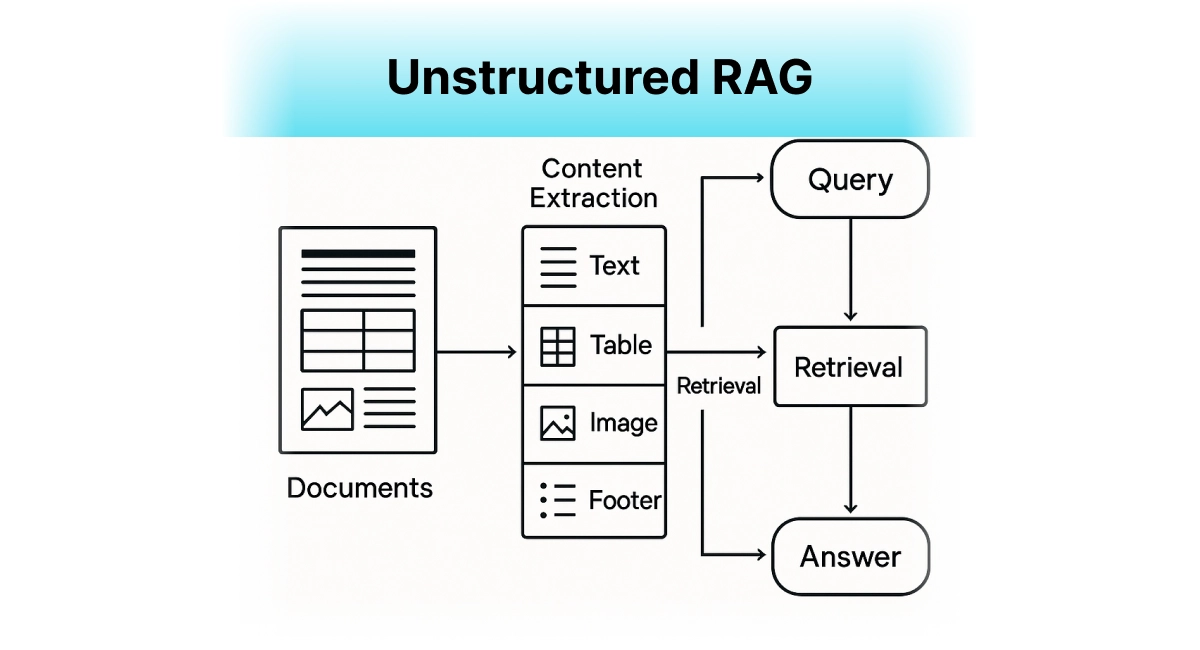
Unstructured RAG
The Problem It Solves
Real documents aren't just text. They have tables, charts, images, and complex layouts that basic RAG completely ignores.
How It Works
Uses specialized tools to extract and understand different types of content - OCR for images, table parsing for structured data, and smart chunking that respects document structure.
When to Use It
- For PDFs with complex layouts
- When dealing with scientific papers, reports, or presentations
- Any time visual information is crucial to understanding
Code Implementation for Unstructured RAG
import os
from enum import Enum
from dataclasses import dataclass
from typing import List, Dict, Tuple, Any, Optional
from langchain.schema import Document
from langchain.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
class ContentType(Enum):
TEXT = "text"
TABLE = "table"
IMAGE = "image"
HEADER = "header"
FOOTER = "footer"
LIST = "list"
FIGURE = "figure"
@dataclass
class ExtractedContent:
"""Container for extracted content with metadata"""
content: str
content_type: ContentType
page_number: int
bbox: Optional[Tuple[float, float, float, float]] = None
metadata: Optional[Dict] = None
source_file: Optional[str] = None
class UnstructuredRAG:
"""RAG system that handles complex document structures and multiple content types"""
def __init__(self, openai_api_key: str):
self.embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
self.llm = OpenAI(openai_api_key=openai_api_key, temperature=0)
self.vector_store = None
self.extracted_contents: List[ExtractedContent] = []
self.documents: List[Document] = []
def search_by_content_type(self, query: str, content_type: ContentType, k: int = 5) -> List[Document]:
"""Search for specific content types"""
if not self.vector_store:
return []
all_results = self.vector_store.similarity_search(query, k=k*3)
filtered_results = [
doc for doc in all_results
if doc.metadata.get("content_type") == content_type.value
]
return filtered_results[:k]
def get_document_structure(self, source_file: str) -> Dict:
"""Get the structure overview of a processed document"""
file_contents = [c for c in self.extracted_contents if c.source_file and os.path.basename(c.source_file) == os.path.basename(source_file)]
structure = {
"total_pages": max((c.page_number for c in file_contents), default=0) + 1,
"content_types": {},
"page_breakdown": {}
}
for content in file_contents:
content_type = content.content_type.value
structure["content_types"][content_type] = structure["content_types"].get(content_type, 0) + 1
page = content.page_number
if page not in structure["page_breakdown"]:
structure["page_breakdown"][page] = []
structure["page_breakdown"][page].append(content_type)
return structure
def query(self, question: str, k: int = 5, include_structure_context: bool = True) -> str:
"""Answer questions using unstructured RAG"""
results = self.vector_store.similarity_search(question, k=k)
contexts = []
for doc in results:
context = doc.page_content
if include_structure_context:
metadata = doc.metadata
source = os.path.basename(metadata.get("source", "unknown"))
page = metadata.get("page", "unknown")
content_type = metadata.get("content_type", "unknown")
context = f"[Source: {source}, Page: {page}, Type: {content_type}]\n{context}"
contexts.append(context)
combined_context = "\n\n---\n\n".join(contexts)
answer_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the following context from various document types (including text, tables, images, etc.),
answer the question as accurately and comprehensively as possible.
When referencing information, please mention the source type (e.g., "according to the table on page X"
or "based on the OCR text from an image").
Context:
{context}
Question: {question}
Answer:
"""
)
chain = answer_prompt | self.llm
answer = chain.invoke({"context": combined_context, "question": question})
return answer.strip()
# Usage example:
unstructured_rag = UnstructuredRAG(openai_api_key="your-openai-api-key")
print("=== UNSTRUCTURED RAG DEMONSTRATION ===")
mock_contents = [
ExtractedContent(
content="Q1 Revenue: $2.5M, Q2 Revenue: $3.1M, Q3 Revenue: $2.8M, Q4 Revenue: $3.4M",
content_type=ContentType.TABLE,
page_number=1,
source_file="financial_report.pdf",
metadata={"structured_data": {"headers": ["Quarter", "Revenue"], "rows": [["Q1", "$2.5M"], ["Q2", "$3.1M"]]}}
),
ExtractedContent(
content="The company's performance exceeded expectations in Q4, driven by strong customer acquisition and retention rates.",
content_type=ContentType.TEXT,
page_number=2,
source_file="financial_report.pdf"
),
ExtractedContent(
content="Chart showing customer growth: January: 1000, February: 1200, March: 1450, April: 1600",
content_type=ContentType.IMAGE,
page_number=3,
source_file="financial_report.pdf",
metadata={"ocr_confidence": "high", "image_size": (800, 600)}
),
ExtractedContent(
content="Executive Summary",
content_type=ContentType.HEADER,
page_number=0,
source_file="financial_report.pdf"
)
]
unstructured_rag.extracted_contents = mock_contents
documents = []
for content in mock_contents:
enhanced_text = f"[{content.content_type.value.upper()}] [FILE: {os.path.basename(content.source_file)}] [PAGE: {content.page_number + 1}]\n{content.content}"
metadata = {
"source": content.source_file,
"page": content.page_number,
"content_type": content.content_type.value,
}
documents.append(Document(page_content=enhanced_text, metadata=metadata))
unstructured_rag.documents = documents
unstructured_rag.vector_store = FAISS.from_documents(documents, unstructured_rag.embeddings)
print("\n=== DOCUMENT STRUCTURE ANALYSIS ===")
structure = unstructured_rag.get_document_structure("financial_report.pdf")
print(f"Document: financial_report.pdf")
print(f"Total pages: {structure['total_pages']}")
print(f"Content types found: {structure['content_types']}")
test_questions = [
"What was the revenue in Q4?",
"How did customer growth change over time?",
"What does the executive summary say?",
"Show me information from tables in the document"
]
print("\n=== QUERY RESULTS ===")
for question in test_questions:
print(f"\nQuestion: {question}")
print("-" * 50)
answer = unstructured_rag.query(question, k=3)
print(f"Answer: {answer}")
print("\n=== CONTENT-TYPE SPECIFIC SEARCH ===")
table_results = unstructured_rag.search_by_content_type("revenue", ContentType.TABLE, k=2)
print(f"Found {len(table_results)} table results for 'revenue':")
for result in table_results:
print(f"- {result.page_content[:100]}...")
Contextual RAG - Working Smarter, Not Harder
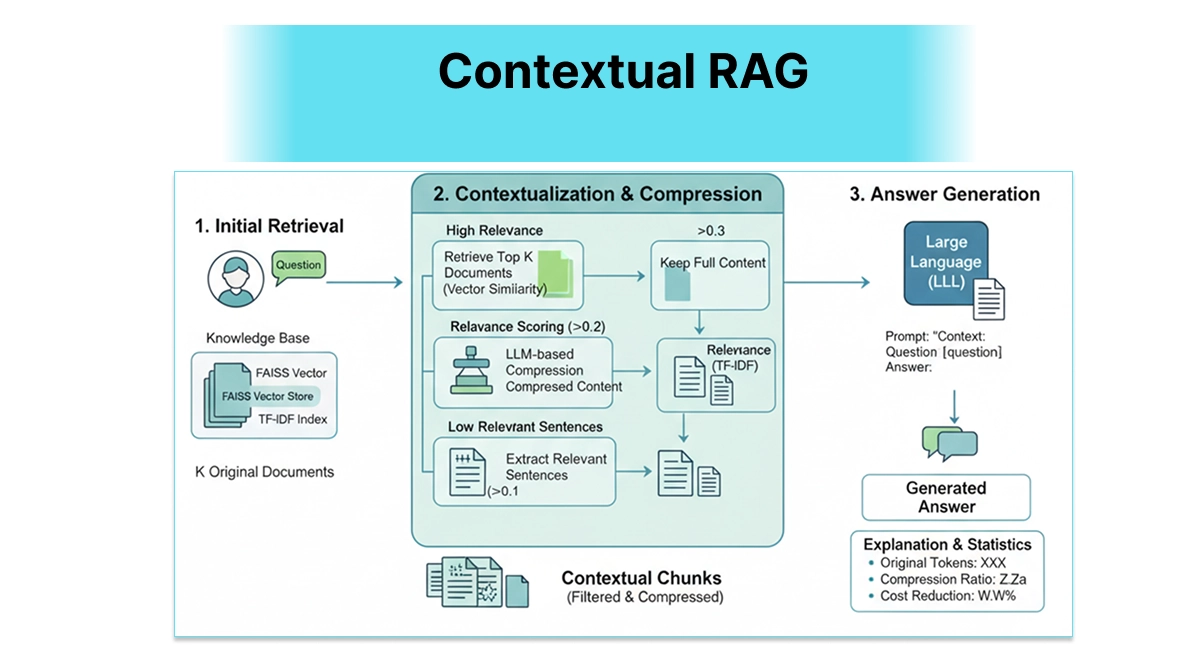
Contextual RAG
The Problem It Solves
Why send a 10,000-token document to your LLM when only 500 tokens are actually relevant?
How It Works
Intelligently compresses retrieved documents by keeping only the information that's actually relevant to answering your question.
When to Use It
- When working with very long documents
- To reduce API costs and improve response speed
- For better focus and accuracy in answers
Simple Implementation for Contextual RAG
import re
import tiktoken
import numpy as np
from dataclasses import dataclass
from typing import List, Dict, Tuple, Optional
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from langchain.schema import Document
from langchain.vectorstores import FAISS
from langchain.prompts import PromptTemplate
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
@dataclass
class ContextualChunk:
"""Enhanced chunk with contextual information"""
content: str
original_content: str
relevance_score: float
compression_ratio: float
context_type: str # 'full', 'compressed', 'extracted'
source_metadata: Dict
class ContextualRAG:
"""RAG system with intelligent context compression and relevance filtering"""
def __init__(self, openai_api_key: str, model_name: str = "gpt-4o-mini",
embedding_model: str = "text-embedding-3-small"):
self.embeddings = OpenAIEmbeddings(api_key=openai_api_key, model=embedding_model)
self.llm = OpenAI(api_key=openai_api_key, model=model_name, temperature=0)
self.vector_store = None
self.documents = []
self.model_name = model_name
try:
self.tokenizer = tiktoken.encoding_for_model(model_name)
except Exception:
self.tokenizer = tiktoken.get_encoding("cl100k_base")
self.tfidf_vectorizer = TfidfVectorizer(max_features=1000, stop_words='english', ngram_range=(1, 2))
self.tfidf_matrix = None
def count_tokens(self, text: str) -> int:
"""Count tokens in text"""
return len(self.tokenizer.encode(text))
def process_documents(self, texts: List[str], chunk_size: int = 1000):
"""Process documents and build both vector store and TF-IDF index"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=100
)
all_chunks = []
for i, text in enumerate(texts):
chunks = splitter.split_text(text)
for j, chunk in enumerate(chunks):
doc = Document(
page_content=chunk,
metadata={
"source_doc": i,
"chunk_id": j,
"original_length": len(chunk),
"token_count": self.count_tokens(chunk)
}
)
all_chunks.append(doc)
self.documents = all_chunks
print(f"Creating embeddings for {len(all_chunks)} chunks...")
self.vector_store = FAISS.from_documents(all_chunks, self.embeddings)
chunk_texts = [doc.page_content for doc in all_chunks]
self.tfidf_matrix = self.tfidf_vectorizer.fit_transform(chunk_texts)
print(f"Processed {len(texts)} documents into {len(all_chunks)} contextual chunks")
def calculate_relevance_score(self, query: str, document_text: str) -> float:
"""Calculate relevance score using TF-IDF similarity"""
try:
query_tfidf = self.tfidf_vectorizer.transform([query])
doc_tfidf = self.tfidf_vectorizer.transform([document_text])
similarity = cosine_similarity(query_tfidf, doc_tfidf)[0][0]
return float(similarity)
except:
query_words = set(query.lower().split())
doc_words = set(document_text.lower().split())
overlap = len(query_words & doc_words)
return overlap / max(len(query_words), 1)
def extract_relevant_sentences(self, text: str, query: str, max_sentences: int = 5) -> str:
"""Extract the most relevant sentences from text"""
sentences = re.split(r'[.!?]+', text)
sentences = [s.strip() for s in sentences if s.strip()]
if len(sentences) <= max_sentences:
return text
sentence_scores = []
for sentence in sentences:
score = self.calculate_relevance_score(query, sentence)
sentence_scores.append((sentence, score))
sentence_scores.sort(key=lambda x: x[1], reverse=True)
top_sentences = [s[0] for s in sentence_scores[:max_sentences]]
result_sentences = []
for sentence in sentences:
if sentence in top_sentences:
result_sentences.append(sentence)
return '. '.join(result_sentences) + '.'
def compress_context_with_llm(self, text: str, query: str, max_tokens: int = 200) -> str:
"""Use LLM to compress context while preserving relevant information"""
current_tokens = self.count_tokens(text)
if current_tokens <= max_tokens:
return text
compression_prompt = PromptTemplate(
input_variables=["text", "query", "max_tokens"],
template="""
Given the following text and query, extract and summarize only the information that is directly relevant
to answering the query. Be concise but preserve all key facts, numbers, and important details.
Target length: approximately {max_tokens} tokens
Query: {query}
Text to compress:
{text}
Compressed relevant information:
"""
)
try:
chain = compression_prompt | self.llm
compressed = chain.invoke({
"text": text,
"query": query,
"max_tokens": max_tokens
})
return compressed.strip()
except Exception as e:
print(f"LLM compression failed: {e}")
return self.extract_relevant_sentences(text, query, max_sentences=3)
def create_contextual_chunks(self, query: str, retrieved_docs: List[Document],
max_total_tokens: int = 2000) -> List[ContextualChunk]:
"""Create contextually relevant and compressed chunks"""
contextual_chunks = []
used_tokens = 0
for doc in retrieved_docs:
if used_tokens >= max_total_tokens:
break
original_content = doc.page_content
original_tokens = self.count_tokens(original_content)
relevance_score = self.calculate_relevance_score(query, original_content)
remaining_budget = max_total_tokens - used_tokens
if relevance_score > 0.3 and original_tokens <= remaining_budget:
final_content = original_content
context_type = "full"
compression_ratio = 1.0
elif relevance_score > 0.2:
target_tokens = min(original_tokens // 2, remaining_budget)
if target_tokens > 50:
final_content = self.compress_context_with_llm(
original_content, query, target_tokens
)
context_type = "compressed"
compression_ratio = self.count_tokens(final_content) / original_tokens
else:
continue
elif relevance_score > 0.1:
final_content = self.extract_relevant_sentences(
original_content, query, max_sentences=2
)
context_type = "extracted"
compression_ratio = len(final_content) / len(original_content)
else:
continue
final_tokens = self.count_tokens(final_content)
if used_tokens + final_tokens <= max_total_tokens:
contextual_chunks.append(ContextualChunk(
content=final_content,
original_content=original_content,
relevance_score=relevance_score,
compression_ratio=compression_ratio,
context_type=context_type,
source_metadata=doc.metadata
))
used_tokens += final_tokens
contextual_chunks.sort(key=lambda x: x.relevance_score, reverse=True)
return contextual_chunks
def explain_contextualization(self, query: str, k: int = 5, max_total_tokens: int = 2000) -> Dict:
"""Explain the contextualization process step by step"""
print(f"\nCONTEXTUAL RAG PROCESS for: '{query}'")
print("=" * 70)
print("\nStep 1: Initial Document Retrieval")
retrieved_docs = self.vector_store.similarity_search(query, k=k)
total_original_tokens = sum(self.count_tokens(doc.page_content) for doc in retrieved_docs)
print(f"Retrieved {len(retrieved_docs)} documents")
print(f"Total original tokens: {total_original_tokens}")
print(f"Token budget: {max_total_tokens}")
print("\nStep 2: Contextualization & Compression")
contextual_chunks = self.create_contextual_chunks(query, retrieved_docs, max_total_tokens)
explanation = {
"query": query,
"original_chunks": len(retrieved_docs),
"original_tokens": total_original_tokens,
"contextual_chunks": len(contextual_chunks),
"final_tokens": sum(self.count_tokens(chunk.content) for chunk in contextual_chunks),
"compression_details": []
}
print(f"Created {len(contextual_chunks)} contextual chunks")
for i, chunk in enumerate(contextual_chunks):
original_tokens = self.count_tokens(chunk.original_content)
final_tokens = self.count_tokens(chunk.content)
print(f"\n Chunk {i+1}:")
print(f" Relevance: {chunk.relevance_score:.3f}")
print(f" Strategy: {chunk.context_type}")
print(f" Tokens: {original_tokens} -> {final_tokens} ({chunk.compression_ratio:.2f}x)")
print(f" Preview: {chunk.content[:100]}...")
explanation["compression_details"].append({
"chunk_id": i,
"relevance_score": chunk.relevance_score,
"context_type": chunk.context_type,
"original_tokens": original_tokens,
"final_tokens": final_tokens,
"compression_ratio": chunk.compression_ratio
})
total_final_tokens = explanation["final_tokens"]
overall_compression = total_final_tokens / total_original_tokens if total_original_tokens > 0 else 0
print(f"\nStep 3: Final Statistics")
print(f"Overall compression: {overall_compression:.2f}x")
print(f"Token reduction: {total_original_tokens - total_final_tokens} tokens saved")
print(f"Cost reduction: ~{(1 - overall_compression) * 100:.1f}%")
explanation.update({
"overall_compression": overall_compression,
"tokens_saved": total_original_tokens - total_final_tokens,
"cost_reduction_percent": (1 - overall_compression) * 100
})
return explanation
def retrieve_contextual(self, query: str, k: int = 5, max_total_tokens: int = 2000) -> List[str]:
"""Retrieve and contextualize documents"""
retrieved_docs = self.vector_store.similarity_search(query, k=k)
contextual_chunks = self.create_contextual_chunks(query, retrieved_docs, max_total_tokens)
return [chunk.content for chunk in contextual_chunks]
def query(self, question: str, k: int = 5, max_context_tokens: int = 2000, explain: bool = False) -> str:
"""Answer questions using contextual RAG"""
if not self.vector_store:
return "No documents processed yet. Please call process_documents() first."
if explain:
self.explain_contextualization(question, k=k, max_total_tokens=max_context_tokens)
contexts = self.retrieve_contextual(question, k=k, max_total_tokens=max_context_tokens)
if not contexts:
return "No relevant context found for the query."
combined_context = "\n\n---\n\n".join(contexts)
context_tokens = self.count_tokens(combined_context)
answer_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
Based on the following carefully selected and compressed context,
answer the question as accurately and completely as possible.
Context:
{context}
Question: {question}
Answer:
"""
)
chain = answer_prompt | self.llm
answer = chain.invoke({"context": combined_context, "question": question})
if explain:
print(f"\nFinal Answer (using {context_tokens} context tokens):")
print("-" * 50)
return answer.strip()
# Usage example:
contextual_rag = ContextualRAG(openai_api_key="your-openai-api-key")
documents = [
"""
The quarterly financial report for TechCorp shows significant growth across multiple sectors.
In Q1 2024, total revenue reached $45.2 million, representing a 23% increase from the previous quarter.
The software division contributed $28.5 million, while hardware sales generated $12.3 million.
Cloud services, our fastest-growing segment, brought in $4.4 million, up 67% year-over-year.
Operating expenses totaled $32.1 million, including $18.2 million in salaries and benefits,
$7.8 million in research and development, $4.1 million in marketing, and $2.0 million in facilities.
Net profit margin improved to 29%, compared to 22% in the same quarter last year.
Looking ahead, the company expects continued growth driven by new product launches in the AI space,
expansion into European markets, and strategic partnerships with major enterprise clients.
The management team remains confident about meeting the annual revenue target of $200 million.
Employee headcount increased by 15% to 847 employees, with most new hires in engineering and sales.
The company also announced plans to open a new development center in Austin, Texas, which will
house up to 200 engineers by the end of 2025.
""",
"""
TechCorp's artificial intelligence initiative, launched in 2023, has become a cornerstone of the
company's strategic direction. The AI Research Lab, led by Dr. Sarah Chen, has developed three
major products: SmartAnalytics for business intelligence, AutoCode for software development
assistance, and ChatAssist for customer service automation.
SmartAnalytics has been deployed by over 150 enterprise clients, generating average efficiency
gains of 34% in data processing tasks. The platform uses advanced machine learning algorithms
to identify patterns in large datasets, predict market trends, and recommend business strategies.
AutoCode, still in beta testing with select partners, promises to reduce software development
time by up to 40%. Early feedback from developers has been overwhelmingly positive, with 89%
rating the tool as 'extremely helpful' or 'very helpful' in their daily work.
ChatAssist handles over 10,000 customer inquiries daily across TechCorp's client base, with
a 94% accuracy rate in problem resolution. The system has reduced average response time from
2.3 hours to 12 minutes, significantly improving customer satisfaction scores.
The AI division plans to double its team size in 2024 and is exploring partnerships with
leading universities for advanced research projects. Initial funding of $25 million has been
allocated for expanding AI capabilities and acquiring specialized talent.
""",
"""
TechCorp's sustainability report highlights the company's commitment to environmental responsibility
and social impact. The company has achieved carbon neutrality for its direct operations and aims
for net-zero emissions across its entire supply chain by 2030.
Energy consumption has been reduced by 35% since 2020 through the installation of solar panels
at all major facilities, LED lighting upgrades, and smart building management systems. The
company now generates 78% of its electricity from renewable sources.
Water usage has decreased by 22% through recycling programs and efficient cooling systems.
Waste reduction initiatives have diverted 85% of office waste from landfills through recycling
and composting programs.
Employee diversity and inclusion efforts have resulted in a workforce that is 47% female and
includes representation from over 30 countries. The company has established mentorship programs,
unconscious bias training, and flexible work arrangements to support all employees.
Community investment totaled $2.8 million in 2023, supporting STEM education programs in
underserved communities, environmental conservation projects, and local economic development
initiatives. Over 400 employees volunteered more than 3,200 hours to community service projects.
The company received B-Corp certification and was recognized by several organizations for its
leadership in corporate social responsibility and sustainable business practices.
"""
]
print("Processing documents for contextual RAG...")
contextual_rag.process_documents(documents)
total_tokens = sum(contextual_rag.count_tokens(doc) for doc in documents)
print(f"Total document tokens: {total_tokens}")
test_questions = [
"What was TechCorp's Q1 revenue and how did it compare to previous periods?",
"Tell me about TechCorp's AI products and their performance metrics",
"What sustainability initiatives has TechCorp implemented?",
"How many employees does TechCorp have and what are their expansion plans?"
]
print("\n" + "="*80)
print("CONTEXTUAL RAG DEMONSTRATION")
print("="*80)
for question in test_questions[:2]:
print(f"\nQUESTION: {question}")
print("="*70)
answer = contextual_rag.query(question, k=5, max_context_tokens=800, explain=True)
print(answer)
print("\n" + "="*70)
print("\n" + "="*80)
print("CONTEXT BUDGET COMPARISON")
print("="*80)
question = "What was TechCorp's financial performance in Q1?"
budgets = [200, 600, 1200]
for budget in budgets:
print(f"\nBUDGET: {budget} tokens")
print("-" * 40)
contexts = contextual_rag.retrieve_contextual(question, k=5, max_total_tokens=budget)
actual_tokens = sum(contextual_rag.count_tokens(ctx) for ctx in contexts)
print(f"Actual tokens used: {actual_tokens}")
print(f"Context preview: {contexts[0][:150] if contexts else 'No context'}...")
answer = contextual_rag.query(question, k=5, max_context_tokens=budget)
print(f"Answer quality: {'Detailed' if len(answer) > 100 else 'Basic'}")
print(f"Answer preview: {answer[:100]}...")
print("\n" + "="*80)
print("COMPRESSION EFFECTIVENESS")
print("="*80)
explanation = contextual_rag.explain_contextualization(
"Tell me about TechCorp's business performance",
k=5,
max_total_tokens=500
)
print(f"\nSUMMARY:")
print(f"- Original tokens: {explanation['original_tokens']}")
print(f"- Final tokens: {explanation['final_tokens']}")
print(f"- Compression ratio: {explanation['overall_compression']:.2f}x")
print(f"- Potential cost savings: {explanation['cost_reduction_percent']:.1f}%")
Choosing Your RAG Strategy
Here's how to pick the right approach for your situation.
Start Simple, Scale Smart
- Begin with Hybrid RAG (it's almost always better than basic vector search)
- Add RAG Fusion if your users ask complex questions
- Consider Graph RAG for knowledge-intensive applications
- Implement Unstructured RAG when you have complex documents
- Use Contextual RAG to optimize costs and performance
Budget and Complexity Considerations
- Traditional + Hybrid RAG: Low complexity, immediate benefits
- RAG Fusion: Medium complexity, great for user-facing apps
- Graph RAG: High complexity, powerful for specialized use cases
- Unstructured RAG: Medium complexity, essential for mixed content
- Contextual RAG: Low complexity, high ROI for cost optimization
Conclusion
We're just scratching the surface of what's possible with advanced RAG techniques. The future likely combines multiple approaches — imagine a system that uses graph relationships, processes multimodal content, generates multiple query perspectives, and intelligently compresses context all at once.
The key is understanding that RAG isn't a single technique — it's a whole toolkit. Start with the approaches that solve your biggest pain points, then gradually add more sophisticated techniques as your needs grow.
The RAG revolution is just getting started. The question isn't whether you should upgrade your approach — it's which improvements you should tackle first.


Author
Co-Authors
