ChatGPT & GPT-4
Plugins ecosystem, real-world knowledge and open-source alternatives.


What is GPT?
GPT stands for Generative Pretrained Transformer. This abbreviation is self-explanatory, but let’s take a closer look at it before we dive into ChatGPT, GPT-4, etc.
Let’s start with the last word: Transformer.
All GPT models, including ChatGPT, are based on Transformer architecture. Transformer architecture became popular with the "Attention is all you need" paper released in 2016 by Vaswani et al.
The fundamental idea behind it was an attention mechanism that provided a way of efficiently using the relevant information from the input data sequence within the architecture with respect to the optimization objective. Since then, transformer architecture has proven to be super stable, meaning that a relatively small amount of changes was required to adapt it to new tasks.
Now transformers are considered one of the most applicable architectures across various domains. Aside from natural language, it has been applied in computer vision, speech processing, graph neural networks, reinforcement learning, time series forecasting, music generation, computational biology, recommender systems, etc.
Nevertheless, the transformer architecture’s initial usage was more extractive than generative, though it was applied to translation.
You might have heard of popular transformer architectures such as BERT, Longformer, etc. These architectures are encoder based and mainly used for extractive tasks such as text classification, named entity recognition, extractive question answering, natural language inference, etc.
On the other hand, GPT is purely a decoder-based architecture with the main task of text generation. Some architectures include encoder and decoder blocks, such as T5, Bart, Pegasus, etc.
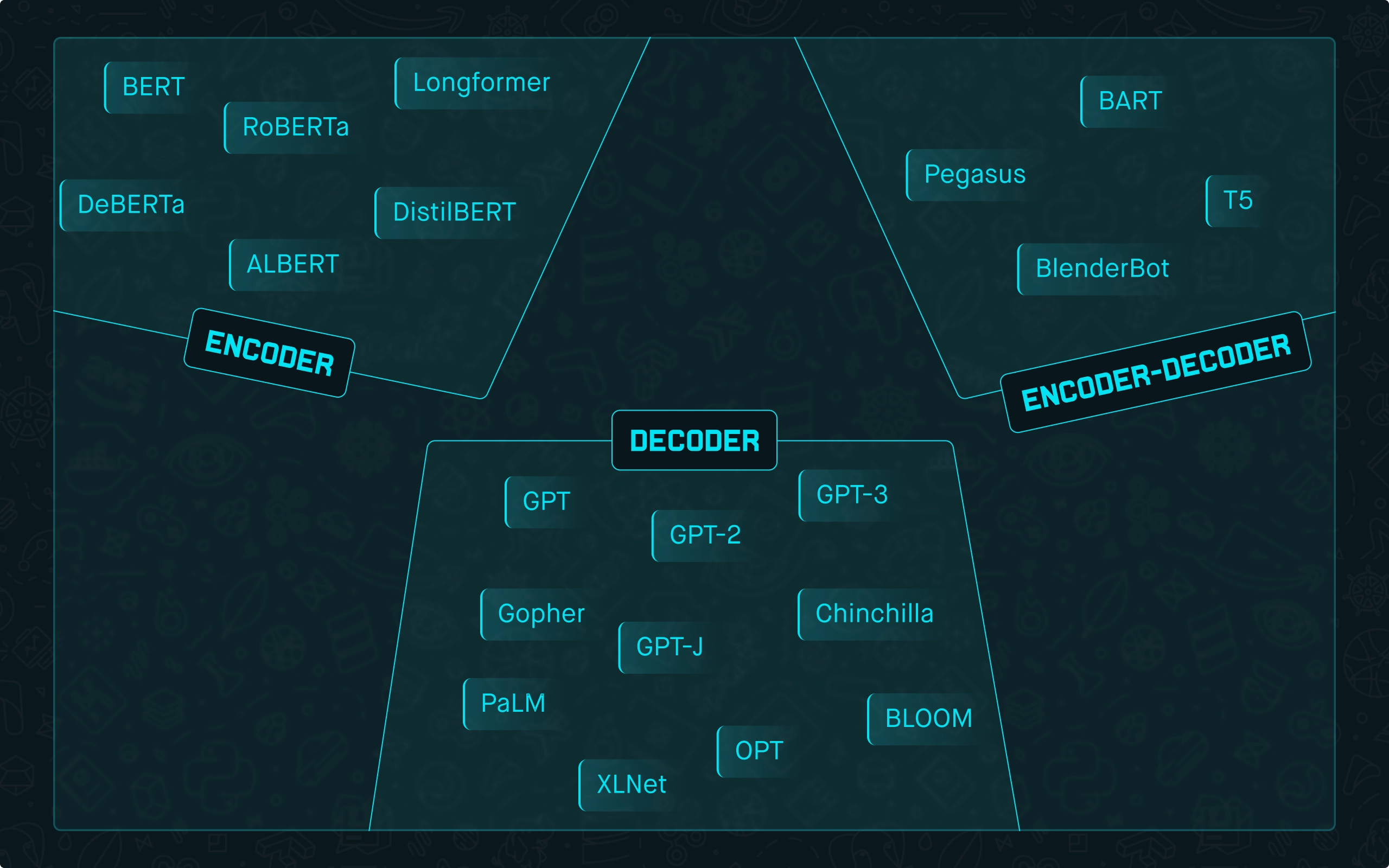
Fig. 1: High-level transformer architectures distribution among popular Language Models.
Now let’s go to the next word from GPT, Pretrained.
Before we use transformers for tasks such as sentiment analysis or generative question answering, they should be pretrained. High-quality pretraining of NLP transformers is an expensive and time-consuming process.
Companies with access to large-scale computing usually do it. Google, Microsoft, Meta, OpenAI, DeepMind, and Amazon are among them.
NLP transformers are also called Language Models (LMs). One of the main drivers behind LMs is data. They are all trained on unsupervised text data. The structure of the language and the text generated worldwide is an excellent source of knowledge.
Encoder-based LMs (BERT, etc.) are mainly pretrained on two tasks called masked language modeling (MLM) and next sentence prediction (NSP).
MLM is a task in which a random word (token, to be more precise) is hidden from the sequence of words. The model is trained to predict that word using the information from the sequence. With this task, the model is trained to understand the local context within the sentence.
NSP is a task in which two sentences are given, and the goal is to learn if they are provided in the correct order, e.g., if the second sentence is a direct continuation of the first sentence.
Decoder LMs are trained to predict the next word in the sequence, as simple as that!
And that’s where the third word: Generative - comes in.
So, the GPT model is a big neural network based on the decoder transformer architecture trained to predict the next word. As you may know, GPT-2, GPT-3, and GPT-4 models already exist.
We won’t dive deep into architectural differences between them as they could be considered minor compared to the difference in their size and the amount of data used for training (and because nobody knows what the GPT-4 architecture is 🙂).
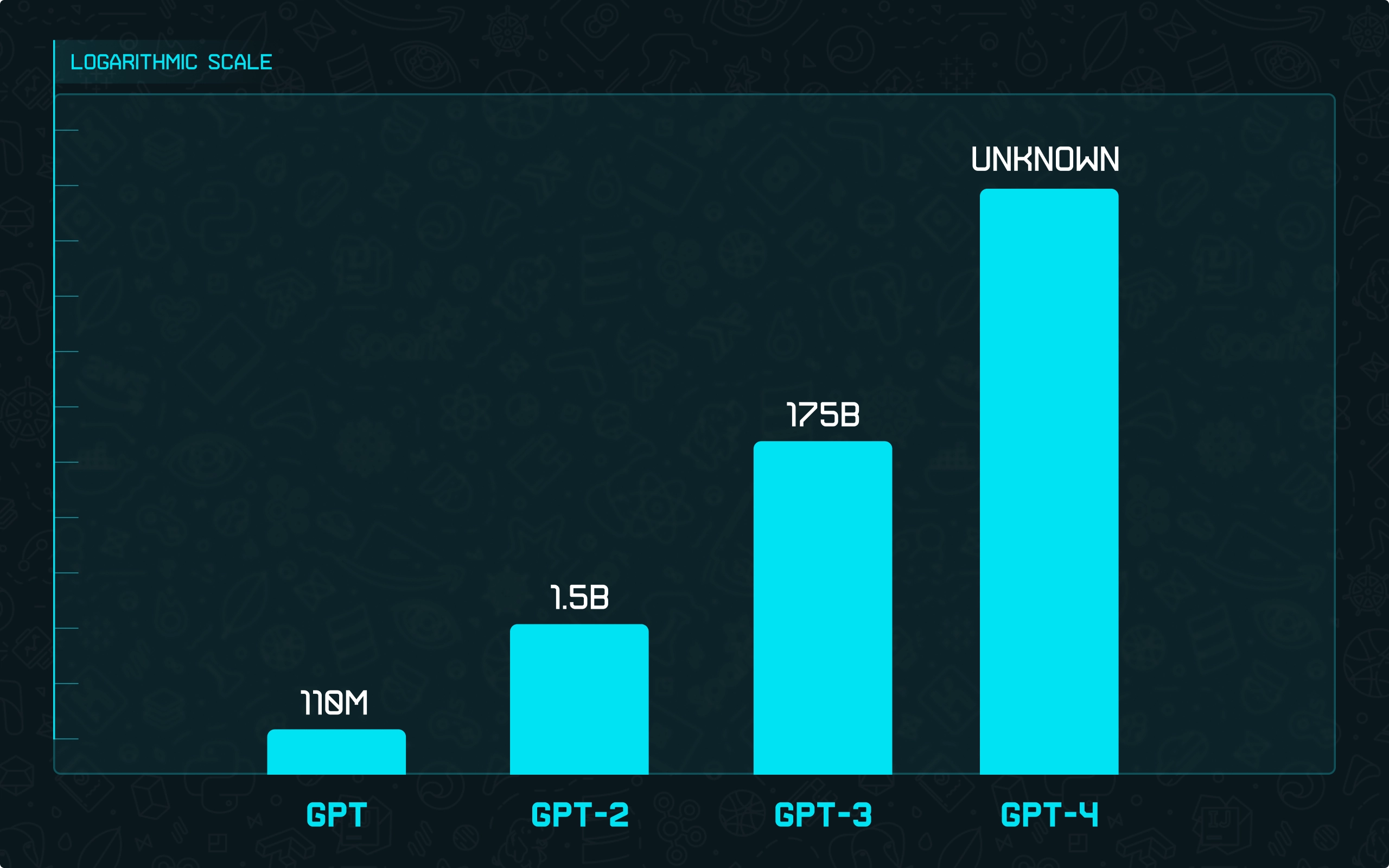
Fig. 2: GPT version sizes comparison on a logarithmic scale.
If you want more detailed information, look at OpenAI papers (and technical report in case of GPT-4) on GPT versions:
What is ChatGPT?
Starting from GPT-3, OpenAI stopped open-sourcing the models as it was with GPT and GPT-2. Also, starting from GPT-3, all models are only available as an API. However, the research paper was released, compared to GPT-4, in which we don’t even know the model’s size.
At the beginning of 2022, they significantly improved GPT-3 pretrained on next-word prediction by introducing a three-step training approach around reinforcement learning from human feedback (RLHF):
-
Gathered example data and trained a guided policy. Labelers showed desired responses for prompts, then GPT-3 was adjusted with this information.
-
Gathered comparison data and developed a reward system. Collected datasets by comparing model responses with labelers choosing their preferred option. Trained a reward system to rank the best answer.
-
Improved the policy using the reward system and PPO. The reward system's output was used as a value. Fine-tuned the guided policy to maximize this value with the PPO technique.
](https://drl.fra1.digitaloceanspaces.com/drl-prod/images/origin/methods_openai_03a754950f.webp?fit=x1200,x800,x400,x256/width=2400)
Fig. 3: Visualization of RLHF process. Source: OpenAI blog
That’s how InstructGPT became available in OpenAI API.
They applied almost the same technique with some changes to chat settings, and that’s how ChatGPT was created. A family of GPT-3 based models trained with the RLHF, including ChatGPT, is also known as GPT-3.5.
The number of model parameters stays the same as in GPT-3. Such index increase is mainly done to mark the significance of improvement achieved with the RLHF.
ChatGPT was released in late 2022 with the expectation to hit around 50k users, but it went viral and hit 4m in the first days.
OpenAI didn’t expect such an interest, and from the AI community perspective, it was somewhat clear why. First of all, some models had similar capabilities, and at the same time, they failed on many simple questions and knowledge prompts in the same way as ChatGPT.
So, from a technical perspective, it was pretty clear that ChatGPT is more of a fun tool that can handle dialogue pretty well. However, people started to use it worldwide for everything, starting from searching instead of using search engines, ending with life and business advice. The natural language interface and the model size that could statistically capture much knowledge had a more substantial effect than expected. And only after a big hype did it become apparent to the average user that ChatGPT, like any other model trained on historical data, doesn’t have access to real-world data.
However, such an interest made ChatGPT the fastest-growing platform, which boosted the creation of OpenAI Plugins that bring actual data into ChatGPT. Currently, the best tasks ChatGPT could solve are so-called local tasks.
The tasks in which most of the information needed for the solution is provided in the prompt.
For example, summarization, rephrasing, code translation (even though there is no target language in the prompt, it’s way more stable compared to code generation), question answering, given the answer is present within the context, etc. Having this said, ChatGPT is still pretty great at solving many problems requiring external knowledge stored in its weights. So, asking different questions would still work way better than anything else.
Here is the list of the main ChatGPT limitations:
-
ChatGPT can produce wrong or nonsensical answers due to training limitations, cautiousness, and misdirection from human demonstrators.
-
The model's responses can vary with slight input phrasing changes, leading to inconsistent answers.
-
It tends to be wordy, overusing phrases due to biases in training data and optimization issues.
-
It often guesses user intent rather than asking for clarification with ambiguous queries.
-
ChatGPT may respond to harmful instructions or show bias.
ChatGPT is available via API for developers and regular users via the interface. For developers, it’s known as gpt-3.5-turbo. For regular users, it can be accessed via the interface here.
ChatGPT serves as a general-purpose interface for a creative content generation or at least as a good starting point. Here is one of the examples that we liked:

Fig. 4: Showcase of ChatGPT response to a decently complex request.
What is GPT-4?
GPT-4 is the most major sign that OpenAI is not open anymore. We don’t know anything about its architecture, number of parameters, or training approach, but we know it’s way better than ChatGPT based on the technical report. Here is the report summary:
We present GPT-4, a large multimodal model for image and text inputs, generating text outputs. Although not as capable as humans, it achieves human-level results on professional and academic tests, like scoring in the top 10% on a simulated bar exam. GPT-4 is a Transformer-based model improved by post-training alignment for factuality and desired behavior. We developed infrastructure and optimization methods for predictable performance at different scales, enabling accurate predictions of GPT-4's capabilities with 1/1,000th of its compute.
So, GPT-4 can work with images. For example, it can write a code of the web page given the sketch of it on a piece of paper. GPT-4 is available as API for developers using gpt-4 as a model.
Currently, it’s provided to a limited number of enterprise customers, but it should be available to everyone soon. For a regular user, it is already available via subscription to ChatGPT Plus, which costs $20 / month.
There are many applications and examples of ChatGPT and GPT-4 usage. Here are a few:
(1) Blender plugin powered by GPT-4.
(2) An example of teaching GPT-4 generating high complexity & quality prompts for Midjourney V5.
(3) A website that can build an arcade game using GPT-4. It doesn’t always do it meaningfully, but it looks pretty cool, at least because of the cases it handles well.
(4) A video game that, aside from GPT-4, also involved a couple of services that helped with the 3D and graphics. The beauty of this is that the author claims to have no coding experience.
(5) AutoGPT is an open-source AI application utilizing GPT-4 to optimize business processes, generate test cases, debug code, and create new ideas. Auto GPT offers internet search capabilities, memory management, GPT-4-based text generation, popular websites, platform integration, and file storage and summarization using GPT-3.5.
GitHub: Auto-GPT
Here are a couple of production usages you might be interested in:
-
Notion uses ChatGPT for better writing: Introducing Notion AI
-
Customer feedback summary generation from Viable: Save hundreds of hours analyzing feedback
-
Interactive stories from Fable: Introducing the Wizard Engine
-
Algolia uses GPT-3 for semantic search: Powering Discovery for your world
-
Microsoft integrated ChatGPT into Bing search engine: Reinventing search with a new AI-powered Microsoft Bing and Edge, your copilot for the web
In general, GPT-4 outperforms any existing AI system. To this matter, there is a letter signed by almost 30k people, among which there are very influential ones like Elon Musk or Youshua Bengio, asking to stop any research that leads to systems of level GPT-4 or above.
How to bring knowledge into ChatGPT?
Before diving a bit into plugins, let’s say you want ChatGPT to be able to answer questions related to the large text document, your website’s FAQ, or even Wikipedia. There is already a solution for that based on the semantic search. The idea is simple:
- User types in a question.
- That question is used to find the correct information (e.g., from text documents, websites, pdfs, etc.).
- Once such pieces of information are found, they are added to the prompt so it becomes easier for ChatGPT to extract the data from those pieces and answer the initial question.
The second step is the one that is most of interest here. How to build such a search engine capable of extracting a small amount of information that is enough to answer the question?
The answer to that is text-embedding-ada-002
This OpenAI API converts any text into a vector. The idea is that vectors of similar texts or pairs of questions and answers would be closer in that space.
So, the way it works is next.
Large text is split into smaller pieces, for example, by paragraph.
Then, each paragraph is converted into an embedding vector. This is done only once and then serves as a search engine database.
After that, each user’s question is transformed into an embedding vector during chat and used to search for the closest vectors corresponding to specific paragraphs.
Finally, those paragraphs are added to the prompt, and ChatGPT uses them to generate a factually grounded answer.
Putting such a semantic search engine converts the task into a local generative question answering that is way easier to solve. A similar idea is used in OpenAI Plugins.
Here is an example of building such a thing in a couple of lines of code.
What are OpenAI Plugins?
As was mentioned above, the biggest issue with ChatGPT was an absence of real-world data in its answers.
OpenAI Plugins solve it.
ChatGPT is the fastest-growing ecosystem at the moment. So, we suggest any customer-facing business think of creating its own Plugin.
They are initially available for a limited group of ChatGPT users and developers, with priority given to some ChatGPT Plus subscribers on the waitlist.
Later, more people and API access will be included.
Currently, a couple of plugins are built by OpenAI, such as browsing, code interpreter, and retrieval.
They’ve open-sourced the retrieval plugin. The first usage is browsing. It utilizes Bing, works sequentially toward the goal, and then uses parsed information to respond correctly.
Numerous plugins are built by companies like Expedia, FiscalNote, Instacart, KAYAK, Klarna, Milo, OpenTable, Shopify, Slack, Speak, Wolfram, and Zapier.
ChatGPT can use a combination of tools in a single reply. It has a mechanism to decide when to use the Plugin.
The idea of bringing external actions or browsing into LMs has been introduced previously.
Numerous research (Augmented Language Models: a Survey, Toolformer: Language Models Can Teach Themselves to Use Tools) attempts exist to do so, as well as products and even open-source tools.
An open-source tool called LangChain already has an open-source UI, so now, it’s possible to create a general-purpose natural language interface for any system, starting with a browser and ending with any OS.
We should soon see a system comparable to Tony Stark’s J.A.R.V.I.S. from Marvel Movie. Eventually, it could be a tool for a business to answer any question and analyze based on internal data. Of course, such tools wouldn’t be using any external APIs as they would operate with confidential information.
So, in combination with a good enough open-source ChatGPT alternative and LangChain, it seems pretty feasible to build.
LangChain already has integrations with browsing, databases, math, and other tools.
Are there any open-source alternatives to ChatGPT?
Yes, there are already good enough open-source alternatives to ChatGPT that you can run on your laptop or phone.
The main spark of progress after ChatGPT was released happened relatively recently, and it’s all due to the release of the LLaMA model by Facebook Research and the accidental leak of its weights.
Compared to other open-source models, LLaMa was trained on way more extensive amounts of public data, which made it that good. Also, it hugely optimizes the inference.
Many open-source ChatGTP-like models are available, but not all are built on LLaMa.
Let’s take a deeper look.
Alpaca
A team from Stanford University created this model. Instruction-following models like GPT-3.5, ChatGPT, Claude, and Bing Chat are powerful but have deficiencies, including generating false information and perpetuating stereotypes.
Academics have struggled to research these models due to limited access. The Alpaca model, fine-tuned from Meta's LLaMA 7B, addresses this issue. On the team’s preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003 while being surprisingly small and easy/cheap to reproduce (<600$).
Blog Post: Alpaca: A Strong, Replicable Instruction-Following Model
GitHub: Stanford Alpaca
Also, there's a nice implementation that brings the Hugging Face PeFT implementation of the LoRA (Low-Rank Adaption) technique that allows training big models, including LMs and Latent Diffusion (e.g., Stable Diffusion), on home-grade GPUs fast.
GitHub: Alpaca-LoRA
Vicuna
Vicuna claims to be better than Alpaca and cheaper to train. Vicuna-13B, an open-source chatbot fine-tuned on LLaMA using conversations from ShareGPT, achieves over 90%* quality of ChatGPT and Google Bard and outperforms LLaMA and Stanford Alpaca in over 90%* of cases.
With a training cost of approximately $300, Vicuna-13B's training and serving code and an online demo are accessible for non-commercial purposes. Preliminary evaluations with GPT-4 as a judge confirm Vicuna-13B's performance.
Blog Post: Vicuna
GitHub: FastChat
Koala
Koala is the model created by BAIR (Berkely Artificial Intelligence Research).
It is similar to Alpaca and mainly focuses on differences in results of models trained on open source and ChatGPT generated.
Blog Post: Koala: A Dialogue Model for Academic Research
Weights: Google Drive
Gpt4All
A LLaMa-based model trained on ~800k prompts generated with gpt-3.5-turbo (API model name for ChatGPT).
The training dataset is more than 10x times what was used for Alpaca. They also trained with the LoRA technique and claimed to outperform Alpaca-LoRA.
Technical Report: GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo
GitHub: GPT4All
CollossalAI
It is an open-source replication of ChatGPT with the entire RLHF pipeline replication. Implementation of the RLHF pipeline is what makes this one stand out.
Blog Post: ColossalChat
GitHub: Colossal-AI

Dolly 2.0
Unlike LLaMa-based models, Dolly and Dolly 2.0 are licensed for commercial use, which makes them very interesting for production applications.
Dolly 2.0 is a 12-billion parameters language model. It is derived from the Pythia model family as well as Open Assistant. It has been specifically fine-tuned using a novel, high-quality dataset of human-generated instructions, which was crowdsourced from Databricks employees.
Blog Post: Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
GitHub: Dolly
Open Assistant
This one also stands out. They have two models: LLaMa-based and Pythia based. The Pythia-based model is free to use in commercial projects. These guys did massive work to create a human-generated dataset of around 600k interactions by 13k volunteers.
So far, we consider this effort the highest quality among all the proposed solutions.
GitHub: Open-Assistant
Have an idea? Let's discuss!

Talk to Yuliya. She will make sure that all is covered. Don't waste time on googling - get all answers from relevant expert in under one hour.


Author
Co-Authors
