Which Speech-to-Text Model Should You Use?
Comparing Accuracy, Latency, and Cost Across Leading STT Solutions


Speech-to-Text (STT) technology has become a foundational component in modern voice-driven applications and as demand grows for accurate and low-latency speech recognition, developers and businesses face a critical question: Which STT model or service should you choose?
The answer isn’t always straightforward. Some solutions prioritize ultra-low latency for real-time use cases, while others offer industry-leading accuracy but only in batch mode. There’s a growing ecosystem of both commercial APIs and open-source models, each with its own trade-offs in speed, cost, flexibility, and language support.
In this article, we dive into a hands-on comparison of leading STT solutions — including open-source models and cloud APIs. We benchmark them across real-world scenarios and provide you with a clear, technical breakdown of how they perform in terms of accuracy (WER), latency, cost and language coverage.
Whether you’re building a live transcription tool, a multilingual voice assistant, or just trying to save on API bills, this guide will help you make the right technical and strategic decision.
Evaluation Metrics: How We Measured STT Performance
This comparison focuses exclusively on streaming Speech-to-Text models, as they are essential for real-time applications such as live transcription, voice assistants, and conversational agents. Unlike batch models that process audio after it’s fully received, streaming models transcribe speech on-the-fly, enabling low-latency interactions, which is a non-negotiable requirement for many real-world use cases.
We evaluated each system based on the following key metrics:
-
Word Error Rate (WER)
WER is the most widely used metric for assessing transcription accuracy. It calculates the percentage of incorrectly recognized words by comparing the model’s output to a reference transcript. Lower WER means better accuracy. For example, a WER of 6.5% means that out of 100 words, ~6 were incorrect. -
Latency
Latency measures how quickly the system produces transcriptions from input audio. For real-time applications (e.g. voice assistants, live captioning), low latency is critical. We evaluated two types:
- First Word Latency (FW Latency): Time taken for the model to emit the first piece of transcription. This metric applies only to real-time streaming models and can fluctuate depending on factors like API load and network conditions.
- Real-Time Factor (RTF): Calculated as the ratio of transcription processing time to the audio duration (transcribe_time / audio_duration). An RTF less than 1 indicates the system transcribes faster than real time, while an RTF greater than 1 means slower than real time.
-
Language Support
The number of languages and dialects supported by the STT engine. Affects generalization and usability across markets. -
Cost
The price charged (in USD) to transcribe one minute of audio, based on published or calculated API pricing. Pricing may vary based on usage tier, feature set (e.g., diarization, timestamps), and transcription mode (streaming vs batch). We used publicly available pricing as of May 2025.
Ultimately, the best model or service depends on your use case. The goal of this comparison is to provide a clear baseline using standard metrics.
But real-world priorities often vary. For real-time applications like live transcription or voice interaction, latency and streaming stability often matter more than perfect accuracy. In contrast, word error rate (WER) is critical for offline use cases like meeting transcription, where accuracy outweighs speed.
Moreover, depending on the specific context, additional factors may also influence model selection, including:
- Speaker diarization (separating multiple speakers)
- Punctuation and casing quality
- Confidence scores per word
- Custom lexicon injection or biasing
- Non-verbal event tagging (e.g., laughter, music)
These features were not benchmarked in this comparison but should be considered when selecting an STT solution for production systems.
Test Setup
To ensure a fair and consistent comparison across all models and services, we designed a unified evaluation pipeline covering both batch and streaming transcription scenarios. For WER evaluation we used jiwer, applying standard normalization chain: RemovePunctuation, ToLowerCase, RemoveMultipleSpaces, Strip.
We selected a test corpus that better reflects real-world performance by avoiding datasets commonly used during model training.
EMILIA Dataset
- Source: EMILIA Corpus
- Description: A multilingual, emotionally-expressive speech dataset featuring naturalistic conversations in English, French, German, and Italian
- Rationale: EMILIA was chosen specifically because it is not included in the training sets of popular STT models (e.g., Whisper, NeMo, Wav2Vec2). This helps provide a more reliable measure of generalization to unseen, conversational, and expressive speech.
- Subset Used: 200 utterances from english subset only (~15 minutes total). Audio was resampled to 16 kHz mono WAV as needed.
- Transcripts: Ground-truth transcripts provided by the dataset authors were used as references for WER computation
Benchmarks
Tables below reflect a real-world, conversational speech scenario (not academic benchmarks), focusing mainly on streaming STT models. The first table consists of open-weight STT models, while the second consists of proprietary models. The performance of the open-weight models was compared on two GPUs — the T4 and the L4. Training experiments were conducted using the Modal cloud.
| Model name | GPUs | Params | RTF | FW Latency | Languages | Streaming | WER |
T4 | 114m | 0.02 | 0.0486 | En only | Yes | 0.1398 | |
L4 | 0.0164 | 0.0505 | No | 0.1292 | |||
T4 | 618m | 0.0254 | 0.0756 | En only | Yes | 0.1122 | |
L4 | 0.0196 | 0.0623 | No | 0.1064 | |||
T4 | 1.06b | 0.0406 | 0.1157 | En only | Yes | 0.2112 | |
L4 | 0.0309 | 0.099 | No | 0.1803 | |||
T4 | 182m | 0.1062 | 0.9399 | 4 | No | 0.2929 | |
L4 | 0.0827 | 0.7579 | |||||
T4 | 1b | 0.3294 | 0.2353 | En + Fr | Yes | 0.0969 | |
L4 | 0.2701 | 0.199 | No | 0.0833 | |||
T4 | 73m | 0.0160 | En only | No* | 0.1232 | ||
L4 | 0.0105 |
*Note: While Faster Whisper base.en does not natively support streaming, community adaptations exist to simulate streaming behavior.
| Model name | RTF | FW Latency | Languages | Cost/min | Streaming | WER |
AssemblyAI Slam-1 | 0.5261 | 0.219 | En only | $0.0061 | Yes | 0.0862 |
AsssemblyAI Nano | 0.5832 | 0.255 | 99 | $0.002 | Yes | 0.1089 |
OpenAI gpt-4o-transcribe | 0.1301 | 0.048 | 57 | $0.006 | Yes | 0.1982 |
Deepgram Nova-3 | 0.2112 | 0.023 | 10 | $0.0043 | Yes | 0.2043 |
OpenAI gpt-4o-mini-transcribe | 0.1649 | 0.037 | 57 | $0.003 | Yes | 0.2048 |
Google V1 default | 0.2248 | 0.211 | 125+ | $0.02 | Yes | 0.2049 |
Faster Whisper base.en | 0.0644 | En only | No* | 0.1233 | ||
Elevenlabs Scribe V1 | 0.1308 | 99 | $0.4 | No | 0.1018 |
As the table shows, trade-offs between speed, accuracy, and cost are unavoidable, and choosing the right STT solution depends heavily on your application needs.
-
The NVIDIA parakeet and Kyutai models perform exceptionally well in streaming setups, especially if you’re comfortable deploying it on your own cloud infrastructure.
-
Parakeet models are optimized for inference on the T4 GPU, so when deploying these models, there will be no significant difference compared to using the more powerful L4 GPU. For other models, as expected, inference on the L4 is faster.
-
If you’re looking for a ready-to-use SaaS solution, Deepgram’s Nova-3 is a strong choice. However, at scale, open-source options tend to offer better long-term value.
-
For non-streaming use cases, we recommend FasterWhisper or ElevenLabs Scribe for their solid accuracy and ease of integration.
Let's Visualize
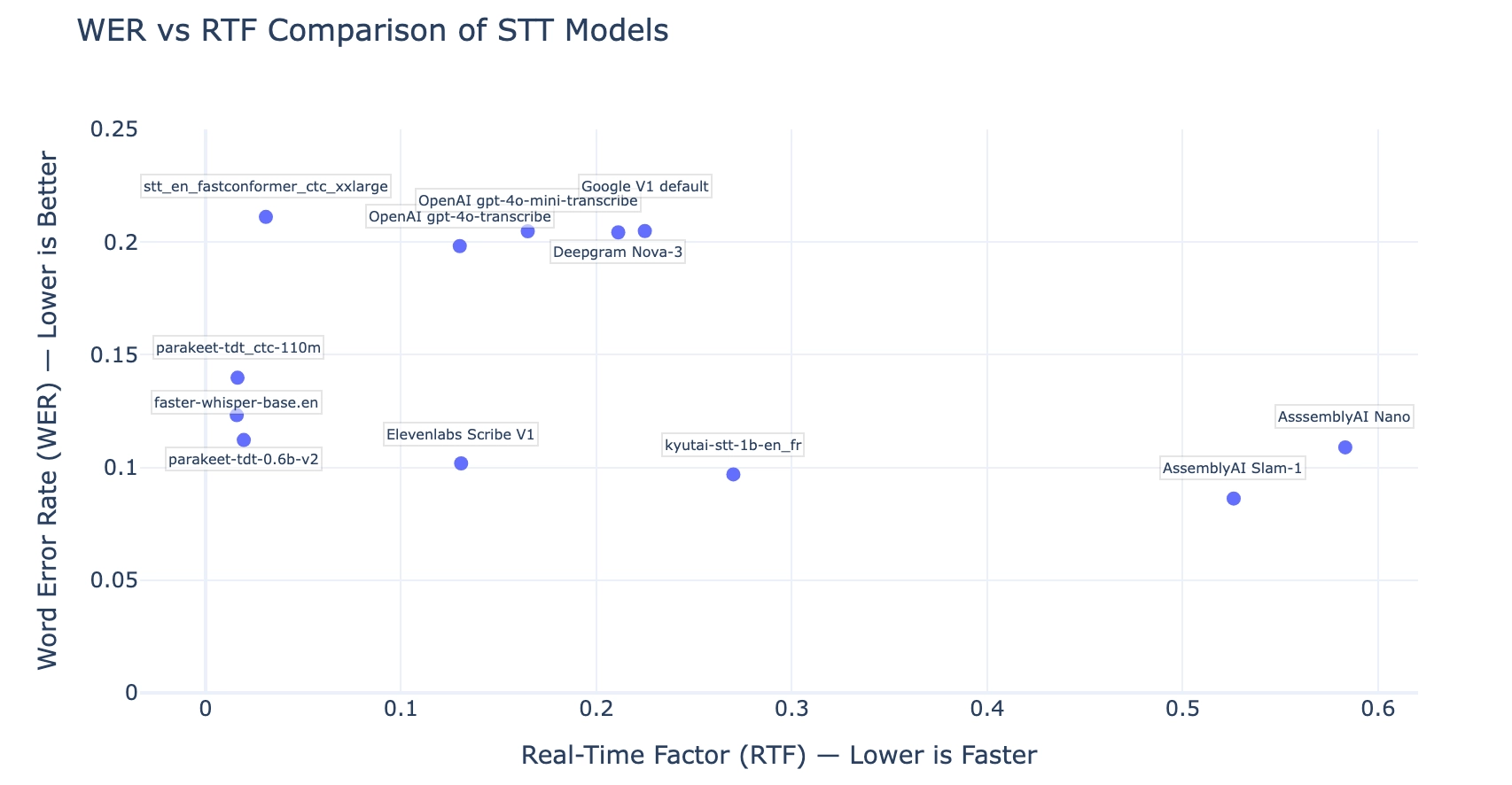
This chart shows how each model balances transcription accuracy (lower WER is better) with processing speed (lower RTF is better). Ideally, you’d want models that fall in the bottom-left quadrant: fast and accurate.
What else to consider
While accuracy and latency are critical metrics, there are several other factors that can significantly impact your choice of a speech-to-text solution in real-world deployments:
-
Adaptability
Some STT services allow you to customize vocabularies, add domain-specific terms, or train models on your own data. This can improve accuracy in specialized contexts like medical, legal, or technical jargon. -
Robustness to Noise
Performance may vary significantly in noisy environments or with speakers who have strong accents or dialects. Testing models in your target environment is essential, especially for applications like call centers or public spaces. -
Data Security
If your application handles sensitive or personal data, check whether the service complies with privacy regulations (e.g., GDPR, HIPAA) and offers encryption or on-premises deployment options. -
Deployment Flexibility
Cloud-based APIs provide ease of use and scalability but depend on network connectivity and may incur higher latency. On-premises or edge deployment options give you more control over data and latency but require more infrastructure management. -
Additional Features
Some services offer advanced features such as speaker diarization (who spoke when), punctuation and capitalization, confidence scores, keyword spotting, or non-verbal event detection (e.g., laughter, music). These can add significant value depending on your use case. -
Rate Limits Understand the service’s limits on concurrent streams, request rates, and total transcription minutes to avoid disruptions in production systems.
Conclusion
- If you’re building real-time applications like voice interfaces or live captions, low latency and streaming stability matter just as much as transcription accuracy.
- Cost becomes a key factor at scale, especially for businesses transcribing thousands of hours monthly.
- Open-source models provide flexibility and cost control but may lag behind in multilingual support and latency.
- Commercial APIs offer powerful out-of-the-box performance, especially for global use cases, but come with usage fees and less model transparency.
There is no one-size-fits-all answer. We recommend:
- Prototyping with multiple services early
- Evaluating on your own data (especially if it’s domain-specific)
- Monitoring performance in production, as API behavior can vary under load or change over time
Ultimately, the best STT model is the one that meets your use case, your users, and your constraints — not just on paper, but in the real world.

Author